
Developers across the globe rely on GitHub for the software development and collaboration that powers their organization. But how safe is your codebase from disruption on the popular web-based platform?
Whether it’s caused by a breach or accidental repository deletion, data loss on GitHub puts businesses at risk of downtime, wasted developer cycles, and lost revenue—and most users don’t know that they share the responsibility of protecting that data with the platform.
In our latest webinar with Dark Reading, our panel of experts from World Wide Web Consortium (W3C) and Rewind gathered to explore strategies for safeguarding GitHub data and share expert insights on how to protect your SaaS data from disaster.
Protecting your GitHub data: A shared responsibility
The webinar kicked off with a sobering reminder: SaaS providers only protect their platform with system-wide disaster recovery, which means that safeguarding account-level data falls squarely on the user.
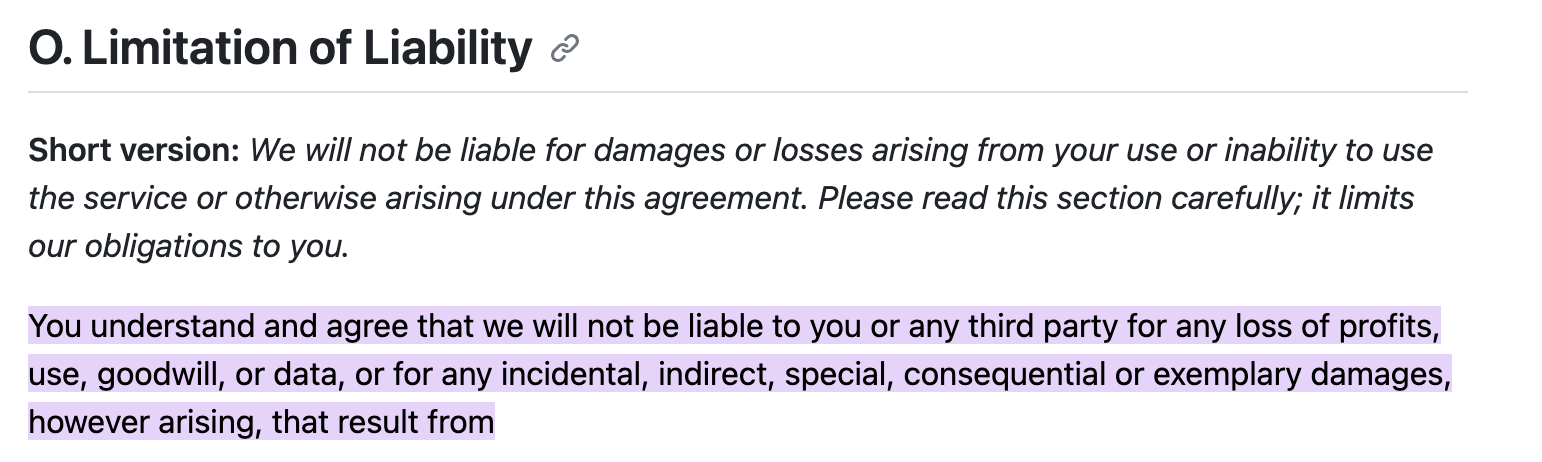
James Ciesielski, Co-Founder and CTO of Rewind, emphasized the importance of understanding the Shared Responsibility Model, which is meant to describe the division of operational responsibility between a cloud service provider and its customers. Essentially, service providers manage their infrastructure at a macro level, but users are responsible for managing and protecting their user-generated individual data. Using GitHub as an example, their Terms of Service clearly state that they will not be liable to you or any third party for any loss of profits, use, goodwill, or data—or for any incidental, indirect, special consequential, or exemplary damages.
A recent Gartner report highlighted that only 15% of enterprises prioritize SaaS backups in 2024, leaving a vast majority vulnerable to cloud data loss. However, Gartner is anticipating that this number will reach 75% by 2028. The reality of a heightened risk of IT outages underscores the need for robust backup strategies, particularly given the increasing reliance on SaaS platforms like GitHub for critical functions such as version control, CI/CD pipelines, and documentation.
Building a comprehensive GitHub backup strategy
Aside from source code, there are many different critical components that live within GitHub. Customers could be using the tool to capture critical documentation, to house information about their product releases, or as part of a change management process. Many companies also use GitHub to manage their infrastructure and even their CI/CD pipeline. Ask yourself: what would happen if any one of those things disappeared? More often than not, the impact on your organization is well beyond what you might initially think.
The best way to start a conversation around backups is to determine your appetite for loss of productivity or reputational damage. When it comes to GitHub specifically, a lot of people tend to focus on source code, and in doing so, they are ignoring all the other ways that GitHub is often used in the software development lifecycle.
Protecting your GitHub code base from disruption ultimately depends on the strategies and tools you have in place to help mitigate risks. During the webinar, James recommends a multilayered effort, including tactics like enforcing multifactor authentication, practicing least privilege access controls, performing tabletop tests and performing regular security audits. Your incident response plan should ideally be anchored in a backup and recovery strategy. This can significantly reduce the likelihood of a major disruption and ensure that your team stays productive even if something goes sideways.
James also emphasizes the importance of adhering to the “3-2-1 backup rule”: three copies of your data, stored in two different locations, with one copy kept outside the SaaS provider’s infrastructure. This is not just the best practice; it is truly your safety net against productivity loss and reputational damage. Backups are not just about recovery—they’re about resilience, and resilience is what keeps your team moving forward no matter what comes your way.
W3C’s data loss experience
Vivien Lacourba, Head of Systems Team, and Denis Ah-Kang, Web Developer & Systems Engineer, share W3C’s journey with GitHub. As a key player in setting global web standards, W3C manages over 1,800 repositories with more than 3,000 contributors across 20 GitHub organizations. These repositories, as well as issues, pull requests, wikis, and more, are key to maintaining records of discussions, decisions, and development of organizational standards.
A few years ago, the team learned that errors can happen at any moment—and while some lead to minor inconveniences, others can have significant consequences. Despite their extensive use of GitHub, an accidental repository deletion highlighted a major vulnerability. While GitHub support was able to restore the repository, the incident served as a wake-up call. W3C realized the need for a reliable backup solution to prevent future disruptions and began exploring alternatives.
The challenges of DIY backups
Initially, W3C attempted to build a custom backup solution using GitHub’s API. However, they faced significant hurdles with this approach:
- Rate limits: GitHub restricts API requests (up to 5,000 per hour), making it challenging to scale backups for organizations with large amounts of repositories, like W3C.
- Incomplete data: Custom scripts often failed to capture all elements of the repositories in the backup, such as wikis and pull request histories.
- Maintenance burden: W3C did not have the resources to keep up with GitHub’s API updates, as the platform is continuously adding new features.
Given these challenges, W3C turned to an automated third-party backup solution to protect their data.
Why choose a third-party solution?
Given the importance of GitHub for W3C, the team needed to find a solution provider that could guarantee proper backups. Rewind offered W3C a scalable, secure, set-it-and-forget-it backup and recovery solution. Key features include:
- Comprehensive backups: Rewind backs up all GitHub data, including issues, pull requests, wikis, and configurations.
- Version history: Rewind offers the ability to restore repositories to specific points in time.
- User management and security: Rewind provides fine-grained access controls and robust security measures, including the user’s choice of where data is stored.
- Adaptability: Rewind continuously updates to align with GitHub’s evolving API and feature set.
For W3C, outsourcing backups allowed them to focus on their core mission of advancing web standards while leaving the complexities of data backups and recovery to the experts.
Balancing costs and benefits
Denis from W3C explained that while Rewind comes with a cost, the benefits far outweigh the expenses. The team now redirects resources previously spent on maintaining custom scripts toward other critical projects. Plus, Rewind’s scalability, automation, and ability to integrate seamlessly with other developer tools ensures W3C’s data security needs are met across the board.
Final takeaways: A proactive approach to GitHub data protection
Businesses looking to assess their data security posture should ask themselves the following questions:
- What is your organization’s tolerance for productivity loss or reputational damage?
- Do you have a clear backup and recovery strategy in place?
- Is your team able to handle the burden of building a custom backup solution, or would you benefit from leveraging third-party expertise to safeguard your critical business data?
The insights shared in this webinar highlight the importance of a proactive approach to GitHub data protection. Whether through custom scripts or third-party solutions, the goal remains the same: ensuring resilience in the face of data loss. Without having a robust data backup and recovery solution in place, the consequences can be dire, including service downtime, wasted developer cycles, and lost revenue.
To learn more about safeguarding the critical GitHub data your organization relies on, watch the full webinar recording and learn more about how Rewind can help.
 Miriam Saslove">
Miriam Saslove">


