Hot Standby for Jira is not the end of the SaaS resilience story. It is the beginning.
For the past decade, the conversation about protecting SaaS data has centered around backup. Make sure your data is copied somewhere. Make sure you can restore it. That was the right conversation to have, and it is still not finished. Most organizations still do not have adequate backup coverage for the SaaS tools their teams depend on.
But those that have solved backup are now asking a harder question: what happens when backup alone is not fast enough? What happens when the disaster is not a deleted file but a corrupted production environment? What happens when Jira itself is unavailable and your entire engineering team is blocked?
Those are three distinct problems. They require three distinct layers of protection. And solving all three is why you need to build SaaS resilience at scale.
Layer one: Backup and recovery
Backup is the foundation. It is non-negotiable, and for most organizations it remains unfinished.
Rewind backs up Jira, Confluence, Bitbucket, GitHub, Azure DevOps, and other critical SaaS tools with schema-aware recovery that understands the relationships between your data, not just the raw records. We provide point-in-time restore as well as granular recovery down to the item level.
This layer is what recovers a deleted item, a corrupted page, or a bulk change that went further than intended. For the vast majority of data loss events, this is the right tool. Get this layer in place before worrying about the ones that follow.
Layer two: Disaster recovery
When the production instance is corrupted, the problem shifts from “recover the data” to “restore operations.” This is the disaster recovery layer, and it requires a fundamentally different approach.
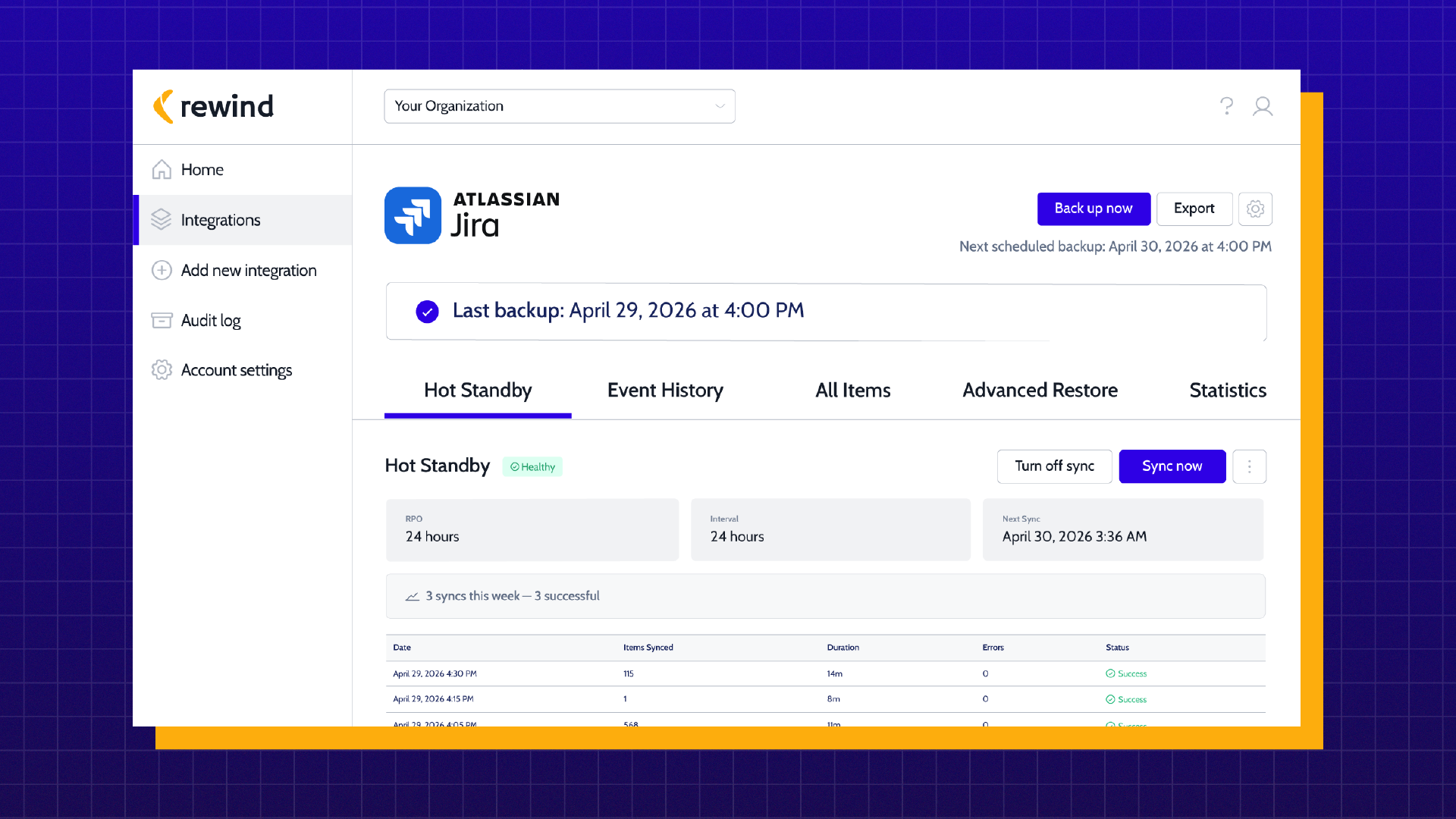
Hot Standby for Jira launches this layer into general availability. It’s a continuously synced secondary instance running in parallel to your production instance. Always on, always ready, hosted in a separate region. When a major data event like an AI agent misfire, a corruption, malware, or a security incident renders your primary Jira unusable, your team can choose to fail over in minutes rather than waiting days or weeks for a full restore.
Near-zero RTO. 24 hours RPO. Full read/write access in a production-like environment.
This is the layer that makes AI adoption genuinely safe. When teams can recover from a data disaster in minutes, they can extend AI permissions rather than restrict them. The productivity gains that AI promises become accessible without the risk of extended downtime undermining them.
Hot Standby for Jira is available now on Rewind’s Advanced plan. Talk to a SaaS resilience expert at Rewind to learn more.
Layer three: Business continuity
The third layer addresses a different failure mode entirely. What if Jira is not corrupted? What if it is simply unavailable because the platform itself is down?
Atlassian outages do happen. Regional SaaS disruptions happen. When they do, teams lose access to their primary workflow tool along with the work items, the boards, the sprint plans, and the coordination layer that keeps engineering moving.
Hot Standby is not designed for this scenario. It runs on Jira infrastructure and is not the right tool when the platform itself is unavailable. A different capability is needed, one that operates independently of the SaaS platform and keeps teams productive in read-only mode while production recovers.
Rewind is building this capability—Pilot Light—coming in Q3 2026. Together with Hot Standby, it completes the failover-ready resilience layer: disaster recovery for data loss and corruption, business continuity for platform outages.
The complete SaaS resilience stack
SaaS resilience is not a single product decision. It is an architecture built in layers, each addressing a distinct failure mode.
Backup and recovery protects against data loss and gives you the ability to restore what was lost. Disaster recovery closes the RTO gap when backup alone is too slow. Business continuity keeps teams productive when the platform itself goes down.
Most organizations have the first layer. Some have started on the second. Very few have all three.
The organizations that do are the ones that can move fastest by deploying AI aggressively, extending agent permissions without second-guessing, and shipping without the fear of unrecoverable downtime hanging over every automation decision.
That is what operating at AI speed actually means. Not just moving fast. Moving fast with the confidence that no matter what goes wrong, you can recover in minutes.
As this resilience stack matures, depth of coverage becomes just as important as the layers themselves. That means not only protecting core Jira data, but the systems teams build on top of it.
That’s where upcoming Xray coverage fits in—coming later in 2026. It will extend backup and recovery to teams using Xray for test management in Jira. Because resilience isn’t complete if critical QA workflows are still exposed.
 Randa Fadly">
Randa Fadly">


