The uptime illusion: Why status pages lie
In a SaaS first world, we have been conditioned to equate uptime with availability. If the vendor’s status page shows a green checkmark, we assume everything is fine.
But uptime and resilience are not the same thing.
A platform can technically be “online” and accessible via a login page, yet your teams are completely blocked by corrupted configurations, broken integrations, or localized outages. When an automation goes rogue or a configuration change cascades through your Jira instance, the vendor’s infrastructure is still up, but your business is down. This gap between system uptime and operational continuity is what costs organizations an estimated $9,000 per minute in downstream disruption.
The Shared Responsibility reality
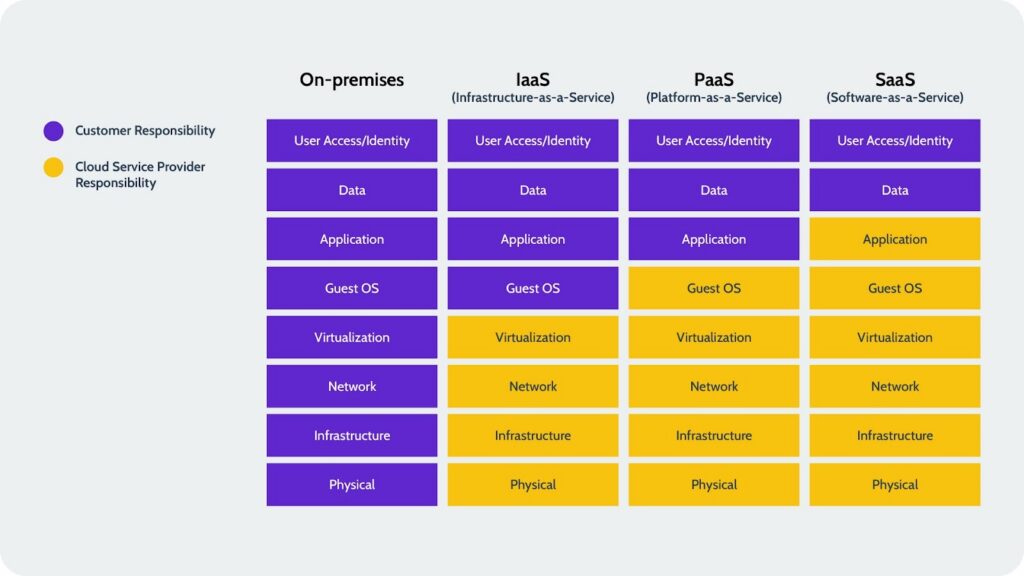
Most organizations operate under a dangerous assumption that the SaaS vendor is responsible for the integrity of the work happening inside the tool. In reality, the SaaS Shared Responsibility Model creates a clear divide. The vendor is responsible for maintaining their global infrastructure, physical security, and application availability. You are responsible for maintaining what flows through that infrastructure: your data, your custom configurations, your user permissions, and your business logic. Native vendor tools and uptime guarantees are designed to solve vendor side problems, not fix your operational failures. They do not help when an internal change creates a full stop for your engineering velocity and product delivery.
The inevitability of disruption and the compliance mandate
Despite best in class infrastructure, downtime still happens and problems still occur. Our research indicates that 60% of organizations experienced at least one to two Jira outages in the past year alone. These are not edge cases; they are a recurring operational reality.
Furthermore, the stakes for maintaining continuity have moved beyond simple productivity. New regulations like DORA and evolving HIPAA requirements mean that having a gap between system uptime and operational readiness is now a compliance risk. In fact, 79% of technology leaders admit their organizations are not completely prepared to comply with these new mandates. Continuity of operations requires more than a promise of system availability; it requires a strategy that protects the audit trails, security structures, and recovery timelines that regulators and executive boards now demand.
Defining SaaS resilience: Lessons from the field
As the “online vs. offline” binary expands and becomes more complex, we have to look at what SaaS resilience actually means in practice.
Resilience is the ability to maintain business momentum when, not if, a critical system faces disruption. But we did not come to this conclusion in isolation: In December 2025, we surveyed IT, engineering, and R&D leaders at large organizations to understand the state of the market. The results, published in our recent SaaS Resilience Report, reveal a massive blind spot. While 69% of organizations require recovery for tools like Jira within four hours, half of those enterprises rely on manual processes or have no formal solution in place to actually meet that target.
Building a failover-ready future
Because of this gap between business expectations and technical reality, Rewind is intentionally building toward a failover-ready future. We are moving beyond reactive restoration to a state of constant readiness, where businesses can keep moving even when a system outage occurs. This involves expanding the intelligence layer of our platform to protect the complex configurations and access models that keep a business functional during a disruption. Our vision is to ensure that when the next disruption hits, your business isn’t another victim of the resilience blind spot. With the capabilities we’re building in your back pocket, your team will be able to keep shipping, no matter what.
 Navid Khazra">
Navid Khazra">