In 2024, Air Canada’s AI chatbot told a customer that bereavement fares could be claimed retroactively. That policy did not exist. The customer booked a flight based on the chatbot’s guidance, applied for the discount, and was denied. He took Air Canada to tribunal and won.
The chatbot could not un-say what it had said. Air Canada could not un-send the message. The liability existed because the action was irreversible, and no amount of AI capability applied after the fact could reconstruct the state that existed before the mistake.
This is the problem that guardrails are not designed to solve.
Prevention is necessary and insufficient
The engineering response to AI risk has largely been a prevention strategy: limit permissions, add policy files, require human review, use guardrails to define what agents should and should not touch. These are the right instincts. A well-configured agent with clear boundaries and appropriate access scope will make fewer mistakes than one running without constraints.
Fewer mistakes is not zero mistakes. And prevention, by definition, operates before an error occurs. It has nothing to say about what happens after one.
An engineering leader at a mid-size SaaS company described a guardrail his team was exploring: an agents.md file deployed with every new repository, instructing any AI agent working in that repo on what it should and should not touch. A reasonable approach. He added a qualifier that is worth noting: “Assuming they follow them.”
Guardrails depend on agents respecting the rules. There is no enforcement mechanism that guarantees compliance. And even a perfectly compliant agent can misinterpret an instruction in a way that produces an unintended outcome within the stated rules.
What AI cannot do after a mistake
When an AI agent corrupts a data state, the instinct is often to ask the agent to fix it. This works for simple, bounded errors. It breaks down in proportion to the complexity of what was changed.
An AI agent can identify that a set of Jira tickets was updated incorrectly. It cannot reliably reconstruct what those tickets contained before the update, because that information no longer exists in the system. It can identify that a Confluence page was overwritten. It cannot recover the version that was replaced unless a recovery system captured it. It can flag that a pull request triggered changes downstream. It cannot trace and reverse every dependency that was affected.
The relationships between data points, the history of states, the context that makes a data record meaningful rather than just syntactically correct: these require a purpose-built recovery layer. They cannot be reconstructed by the same agent that made the mistake, or by a different agent with access to the current state of a corrupted system.
This is not a limitation of current AI capability. It is a structural property of what it means for data to be lost or corrupted. You cannot recover what was not captured.
The speed problem compounds the recovery problem
AI agents act fast. A mistake that would take a human engineer hours to make can propagate in seconds. By the time the error is caught, reviewed, and escalated, it has already affected downstream systems, triggered automated workflows, and been read by other agents that incorporated the corrupted state into their own outputs.
The window between a mistake and its detection is not shrinking. In many cases, it is expanding, because AI-generated changes look syntactically correct even when they are semantically wrong. A ticket that was recategorized incorrectly by an agent still looks like a valid ticket. A Confluence page that was rewritten by an agent still looks like documentation. The error is not obvious from the surface.
By the time the mistake surfaces, the data state that needs to be recovered may be several steps removed from the original error. Prevention strategies that reduce the odds of a mistake do not address the gap between when a mistake happens and when it is caught.
Recovery is an architectural layer, not a fallback
The framing of recovery as a last resort misses what it actually is: a structural component of any system where mistakes are possible and the cost of a mistake is meaningful.
Rewind captures point-in-time data states across Jira, Confluence, and GitHub with schema-aware fidelity. This means not just the data, but the relationships between records, the metadata, the configuration: the context that makes a restore actually useful rather than technically complete but practically broken.
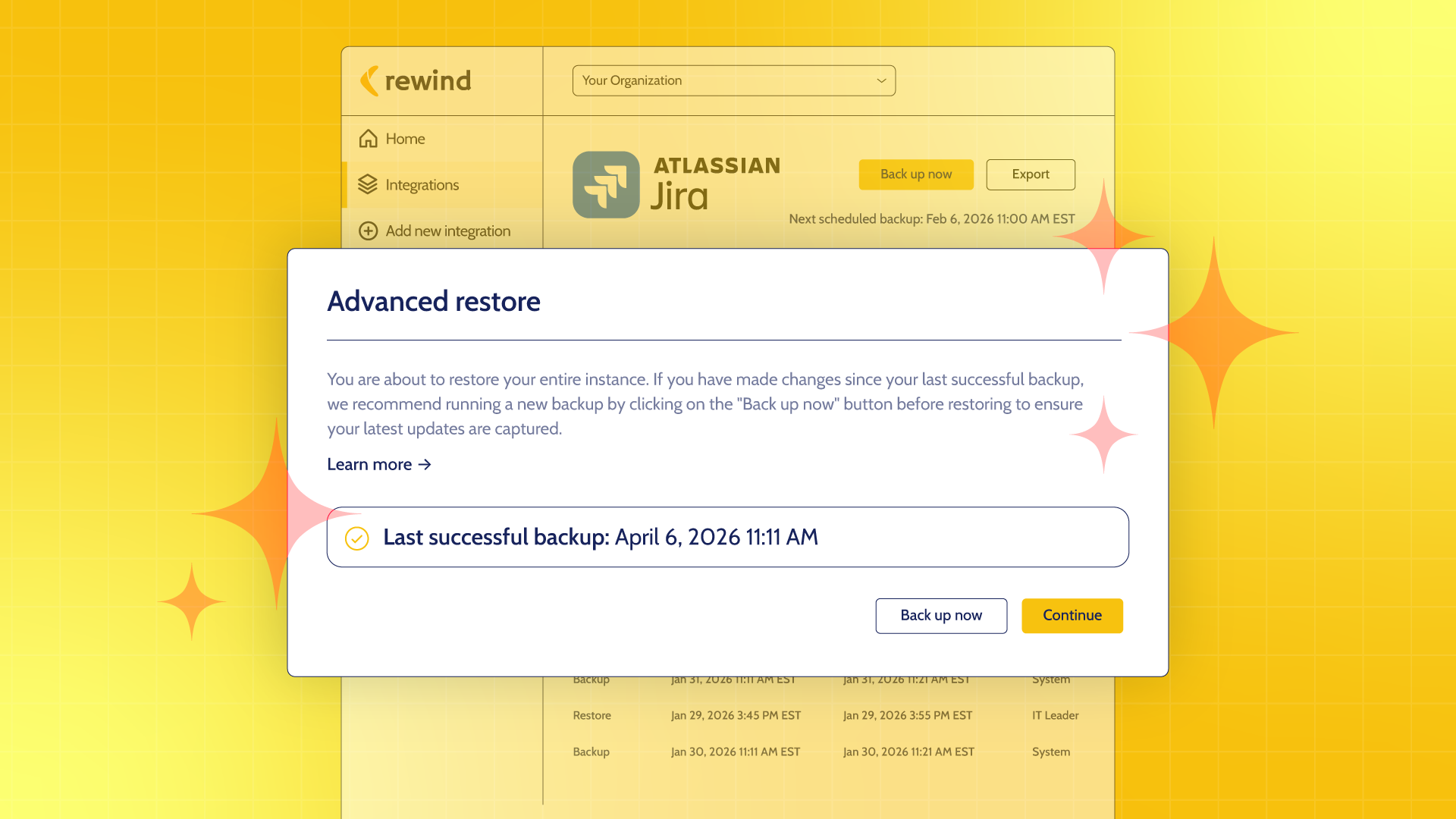
When an AI agent causes a data problem, the recovery question is not “can we figure out what it was?” It is “when was the last clean state, and can we restore to it?” With point-in-time recovery in place, the answer is yes. Not reconstructed. Not estimated. Restored.
The teams that have built the full stack
Engineering teams that have thought seriously about AI risk do not choose between prevention and recovery. They build both, because they understand that prevention reduces frequency and recovery reduces impact, and that a resilient system requires both properties.
Prevention is the first line. Recovery is what makes the first line enough. Together, they change the calculus for AI adoption: if the downside of a mistake is bounded by the ability to recover, the rational response to risk is not restriction. It is confidence.
That is the full stack. Guardrails on the front end. Point-in-time recovery on the back. And teams that can actually take the limits off their AI.
Rewind provides schema-aware, cross-platform backup and point-in-time recovery for the SaaS tools engineering teams depend on, including Jira, Confluence, and GitHub. More than 25,000 organizations worldwide trust Rewind to keep their teams shipping.