Here’s a question most engineering organizations cannot answer cleanly: at any given moment, how many AI agents are running with access to your production systems, who authorized each one, and what did they do overnight?
For many teams, the honest answer is some variation of: we are not sure. Someone on the platform team spun up an agent last month. A few developers are running their own. There might be an automated workflow the DevOps team connected to the ticketing system. It is not centrally tracked.
This is not a failure of intent. It is a structural consequence of how AI tools proliferate.
How governance gaps form
AI tools spread differently from traditional software. Traditional software requires IT approval, security review, procurement sign-off. The adoption cycle has friction, and that friction creates visibility. Someone knows what was deployed, when, and with what access.
AI agents do not work that way. Any developer with API access and thirty minutes can spin up an agent, connect it to production systems, and have it running by the end of a standup. The barrier to deployment is low by design. That is part of the value.
An engineering leader at a mid-size SaaS company described it directly: “We’re building these tools and we’re like, who’s managing them? How do you handle the security of them? Because anyone can spin them up, basically.”
The tools that generate the most productivity often generate the least governance visibility. By the time an organization tries to map what is running, agents have already accumulated months of access history that no one has reviewed.
Why guardrails are not a governance strategy
The standard response to AI governance concerns is to add guardrails: policy files that instruct agents on what to touch and what to avoid, permission scopes that limit access to specific systems, review gates that require human approval before certain actions.
Guardrails are valuable. They are not a governance strategy.
Governance requires accountability after the fact, not just constraints before it. A guardrail defines what an agent should do. It does not create a record of what it actually did, whether that record is legible to a human reviewer, or whether the actions taken at 2 AM on a Tuesday are traceable to a specific agent with a specific authorization scope.
The engineering leader building agents.md policy files acknowledged the gap himself: agents will follow the rules, “assuming they follow them.” The policy exists. Verification does not.
The audit problem
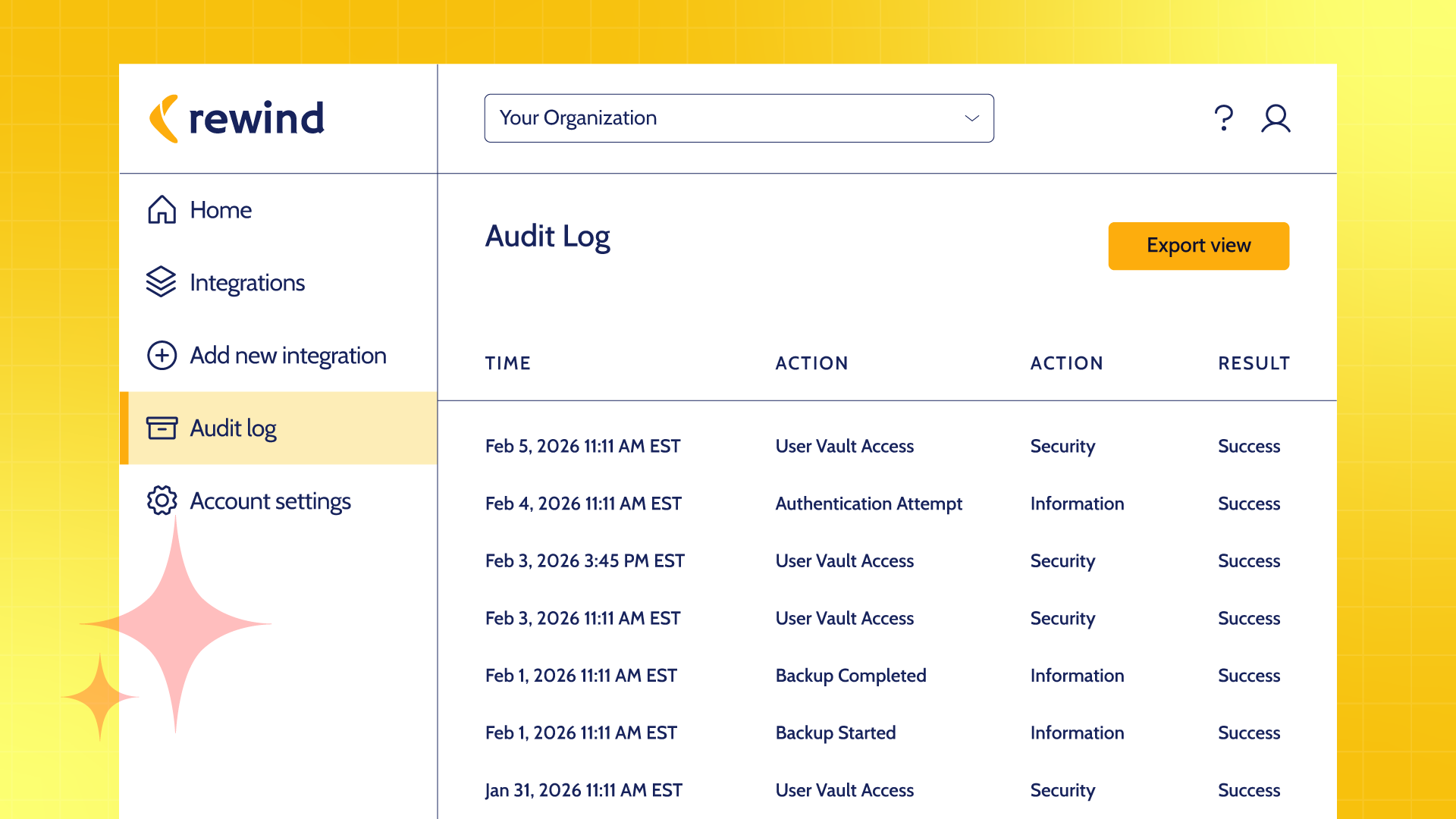
When something goes wrong in a system where AI agents have been active, the investigation begins with a question: what changed, when, and what caused it? In a human-operated system, that question has a tractable answer. Engineers leave traces. Git commits have authors. Jira updates have timestamps and user attribution. The audit trail is incomplete but navigable.
In an AI-agent-operated system, the audit problem is harder. Agents can make changes at high volume, across multiple platforms, faster than human review cycles. An agent that updates 200 Jira tickets overnight based on a workflow trigger has left 200 data points that look like routine activity. Identifying which of those updates was incorrect, what the correct state was before the update, and what downstream effects propagated from the error requires tooling that most teams do not have in place.
80% of organizations lack a formal GenAI risk management plan (Veeam / IBM). That number is not surprising given how fast adoption has moved. It reflects a real gap between deployment velocity and governance maturity.
What governance actually requires
Effective AI governance is not primarily a policy problem. It is a visibility and recoverability problem.
Policy tells agents how to behave. Visibility tells humans what agents actually did. Recoverability tells teams what they can do about it. All three are necessary. Most organizations have made progress on the first and almost none on the second and third.
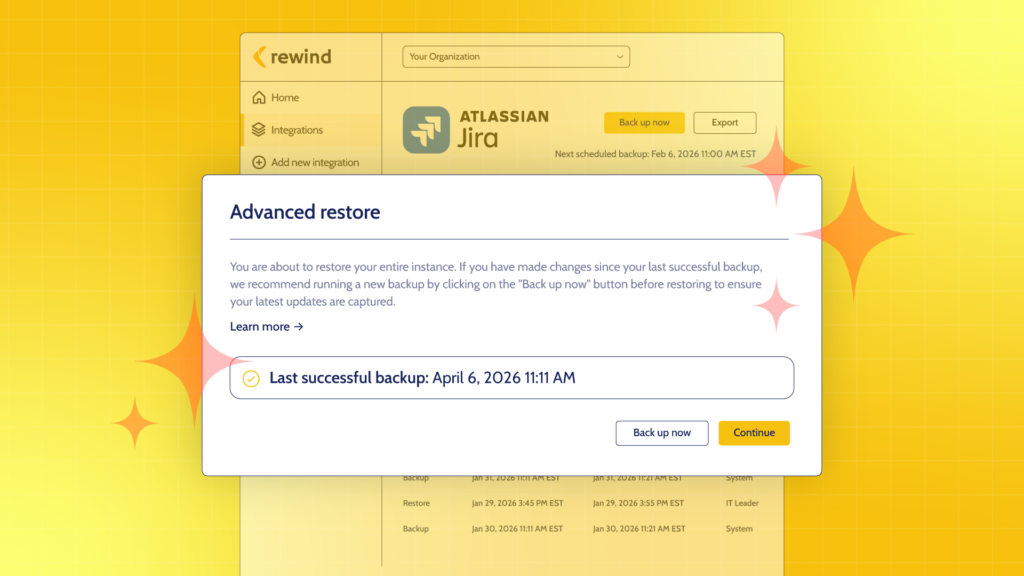
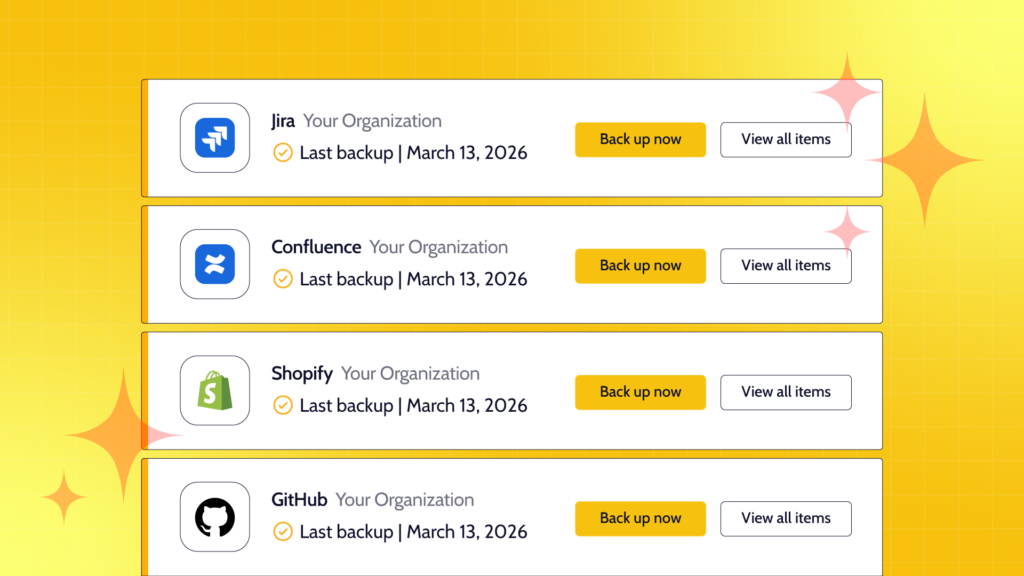
Rewind provides point-in-time data recovery across the platforms AI agents work in, including Jira, Confluence, and GitHub. This creates a recoverable record of data states across systems: not just what changed, but what the state was before the change, at any point in time. When an investigation requires understanding what an agent did at 2 AM, the answer is not a manual log review. It is a restore to the state that preceded the action in question.
This is what makes governance tractable in practice. Not stricter policies. Not more approval gates. A recovery capability that makes AI agent actions auditable and reversible after the fact.
The organizations getting governance right
The engineering organizations that have built effective AI governance frameworks share a common characteristic. They did not try to govern AI by slowing it down. They built the infrastructure that makes fast AI governable.
They know what agents have access to. They can trace what changed and when. And when something goes wrong, they can restore the correct state across every platform the agent touched, without a manual reconstruction effort.
That combination, visibility plus recoverability, is what turns AI governance from a risk management exercise into a competitive advantage. Teams that have it can adopt AI faster, give agents broader access, and respond to mistakes with confidence instead of crisis.
The question is not whether to govern AI agents. It is whether to build governance that slows adoption or governance that enables it.
Rewind provides schema-aware, cross-platform backup and point-in-time recovery for the SaaS tools engineering teams depend on, including Jira, Confluence, and GitHub. More than 25,000 organizations worldwide trust Rewind to keep their teams shipping.