What’s the data disaster your team is most likely to face in 2026? Here’s a hint: your disaster recovery plan won’t cover it.
It will not start with a hardware failure or a ransomware notice delivered at 3 AM. It will start with a workflow that ran correctly, then ran at scale, then ran on the wrong data. It will start with an AI agent given broad permissions and a task that seemed well-defined—until it was not. It will start in seconds, propagate across thousands of records, and be discovered hours later by someone who notices something that should not have changed.
This is the new face of data disasters. And most organizations are not ready for it.
What data disasters used to look like
For most of Rewind’s history, we helped customers recover from data loss incidents that followed predictable patterns: A user deleted something they should not have. An admin made a bulk change that went further than intended. A third-party integration overwrote data it should not have touched.
These incidents were damaging, but they were also bounded. A human made a mistake. The mistake affected a finite scope. You identified what was wrong, found the right restore point, and recovered what was lost.
The recovery tools built for this world—the ones that feature granular restore, point-in-time recovery, and version history—assume a human-scale problem. They help solve problems caused by human-scale mistakes.
AI agents do not make human-scale mistakes.
What AI changed
A single AI agent can move 16x more data than all human users on a platform combined. That is not a projection. That is a measured figure from security research published in 2025.
When an AI agent operates with write access to your Jira environment, it does not pause between actions. It does not second-guess its scope. It executes at the speed at which it was designed to operate. A misconfigured prompt, an automation that ran against the wrong project filter, a bulk reclassification that touched every issue instead of a subset: any of these can propagate across thousands or millions of records, all before a human has finished reading the first notification.
80%of organizations still lack a formal GenAI risk plan. That means most teams are deploying AI agents with no documented answer to the question: “What happens when one of them causes a major data event?”
The incidents are already happening. These are not hypothetical risks. They are the incidents your customers, competitors, and peers are experiencing now.
Why your recovery plan was not built for this
The recovery tools designed for human-scale mistakes work by restoring from just before the moment something went wrong. That approach works when the mistake is bounded: one deleted item, one bad change, one corrupted record.
When it comes to recovery, AI-driven data disasters are different in two ways.
First, the scope. An AI agent can corrupt thousands of Jira issues across dozens of projects in a single operation. Granular restore becomes impractical at that scale. You are not recovering one item. You are recovering a production environment.
Second, the timeline. When the scope of a disaster is large enough to require a full instance restore, the recovery time means that the incident enters a new category. For organizations with tens of millions of Jira items, a full restore can take 27 days or more. That is not a recovery incident. That is an extended outage.
Your backup strategy was built to make sure the data exists. It was not built to get you back to work in the timeframe that an AI-era incident demands.
What recovery looks like now
The answer is not to restrict AI. The teams pulling ahead in 2026 are the ones using AI aggressively, not cautiously. Restricting AI to avoid data risk is like slowing your car to avoid the possibility of a flat tire. You have not removed the risk. You have just paid the cost upfront, in productivity, every day.
The answer? Recovery infrastructure that matches the speed and scale of the threat.
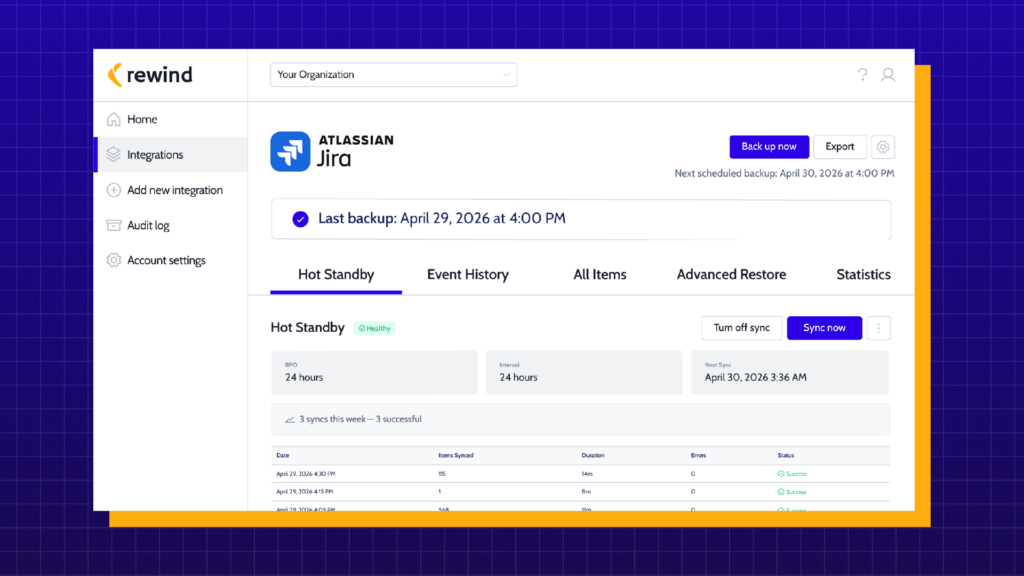
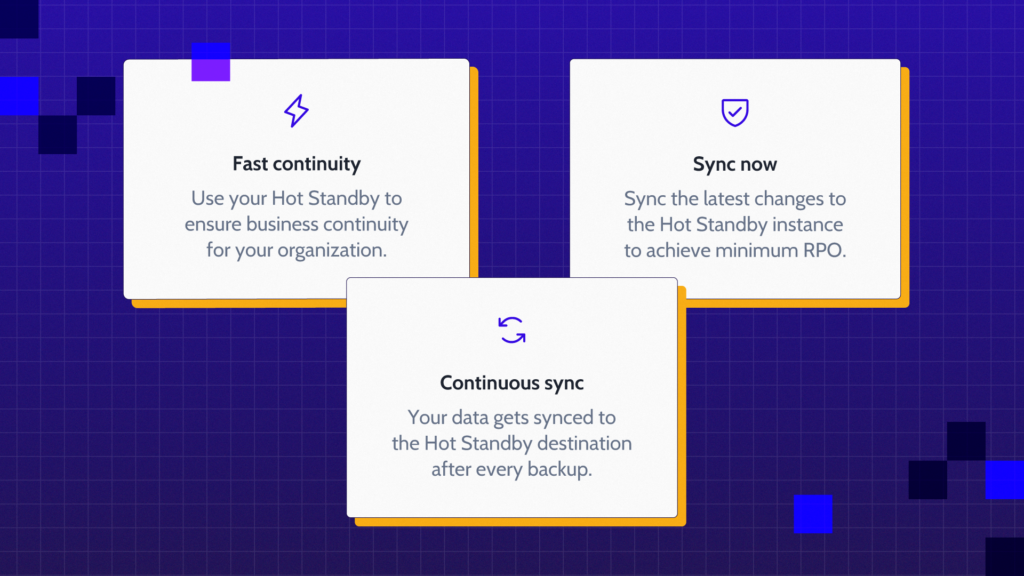
For human-scale incidents, that means granular restore and point-in-time recovery. For years, Rewind has provided this across Jira, Confluence, GitHub, Bitbucket, and more. These tools still work for the bounded, recoverable mistakes that still make up the majority of data loss events.
For AI-scale disasters, where the production instance is corrupted, unusable, or too damaged to restore granularly within an acceptable timeframe, the answer requires something more. The question shifts from “can we get the data back?” to “how fast can we get the team back to work?”
That is a question about the Recovery Time Objective. And it is the question most organizations have not answered yet.
What is your actual RTO for Jira? Not the number in your DR documentation. The number you would experience tomorrow if a data disaster hit your production instance today. More to come in our next blog!.
Sources:
– Obsidian Security, 2025: single AI agent moves 16x more data than all human users combined
– Veeam / IBM: 80% of organizations lack a formal GenAI risk plan
– Rewind internal research, Q1 2026: full instance restore times for large Jira instances
 Randa Fadly">
Randa Fadly">