
With the increased adoption of continuous deployment, more and more organizations have increased their deployment frequency in order to get their latest products into the hands of their customers as quickly as possible. A compliment to this fast-paced deployment practice is continuous auditing. Both of these approaches constitute a leftward shift from the more traditional methodologies of software development.
This increased rate of deployment can lead to the occasional necessity for an emergency hotfix. Like many organizations, we are using GitHub to build and deploy our software. In some cases, emergency fixes are required to avoid real-world consequences including downtime or the degradation of services. Having these changes documented as code (rather than manipulating resources in a web console) is preferred. In many cases, MTTR (Mean time to repair) is more advantageous than MTTR (Mean time to resolve). At times, an emergency hotfix can solve the problem immediately, allowing for the appropriate retrospective to be spent on working towards a longer-term solution to the underlying problem.
At Rewind, we follow a change management process as part of SOC 2 compliance. This process allows for emergency changes, whereby changes can be approved but without the usual number of reviews for the change. There are times when an emergency fix may need to be released to production quickly, but allowing production engineers or alike the ability to impact production in emergency situations should be audited.
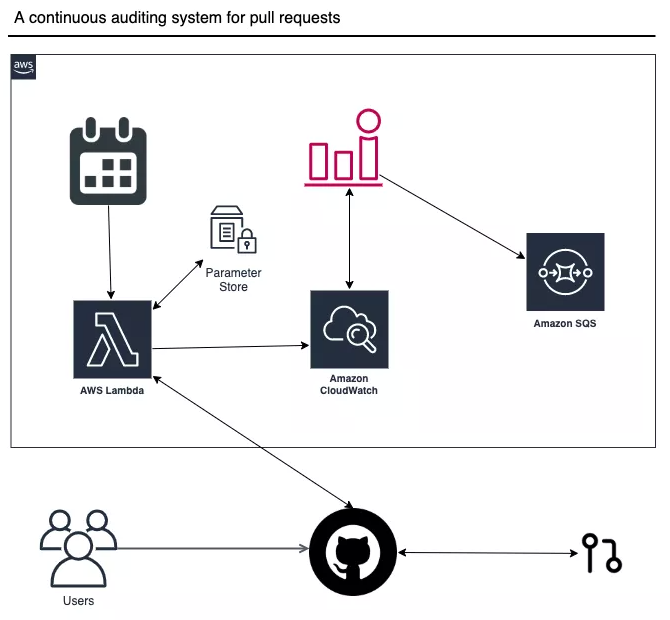
Working in conjunction with our SOC 2 auditor, we have developed (and open-sourced) tooling to scan pull requests within a specified time window leveraging GitHub’s search syntax. If any pull requests are found by the search query, they are logged in AWS CloudWatch Logs and the relevant CloudWatch Alarms are sent to SQS and then picked up by our operations team.
This notifies us of any emergency changes so that we can track the reason for the emergency change (required for SOC2 auditing) and triage them if necessary. This allows us to trust but verify, and also retain these records for an extended period of time, since GitHub only stores audit logs for 90 days. Certifications such as SOC 2 require a well-documented change management process and procedure, including how to deal with emergency changes and how these changes are audited.
How to Set Up a Continuous Code Monitor
The solution uses AWS SAM and its CLI to build, package, and deploy an AWS Lambda (written in Ruby). To reduce the size of the Lambda package, we leveraged AWS Lambda layers to package up our dependencies separately.
See the following CloudFormation snippet:
AuditorLambdaFunction:
Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction
Properties:
CodeUri: src/
Handler: lambda.handler
MemorySize: 384
ReservedConcurrentExecutions: 1
Role: !GetAtt LambdaRole.Arn
Runtime: ruby2.7
Timeout: 300
Layers:
- !Ref AuditorLambdaLayer
Environment:
Variables:
GITHUB_ORG_NAME: !Ref GitHubOrgName
GITHUB_TOKEN_SSM_PATH: !Ref GitHubTokenSSMPath
LAST_TIME_CHECKED_SSM_PATH: !Ref LastTimeCheckedSSMPath
Tags:
function: github-pr-auditor
service: common
platform: common
lambda: github-pr-auditor
region: !Ref AWS::Region
AuditorLambdaLayer:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: github-pr-auditor-dependencies
Description: Dependencies for github-pr-auditor
ContentUri: lambda_layer
CompatibleRuntimes:
- ruby2.7
RetentionPolicy: Retain
Metadata:
BuildMethod: makefile
As you can see above, the Function is dependent upon a single layer called AuditorLambdaLayer. The layer is packaged up separately and contains all of the dependencies defined in the Gemfile.lock necessary to run the application. One caveat we ran into was that SAM does not package up ruby gems (for Lambda Layers) in a way that the Lambda runtime is expecting. Luckily we found this issue and were able to work around it by reorganizing the files in the Layer by making use of a custom Makefile.
After ensuring that the Lambda itself ran as expected, we set up an AWS Events Rule to run the Lambda on a schedule. The following CloudFormation snippet defines this:
LambdaSchedule:
Type: "AWS::Events::Rule"
Properties:
Description: >
A schedule for the Lambda function.
ScheduleExpression: !Ref LambdaRate
State: ENABLED
Targets:
- Arn: !Sub ${AuditorLambdaFunction.Arn}
Id: LambdaSchedule
Schedule Expressions for Rules can be defined as strings such as “rate(24 hours)” or “rate(5 minutes)” depending on how frequently you want to run the code.
The last piece of the puzzle was to ensure that alarms would notify us when a certain type of log appeared.
EmergencyChangeAlarm:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmName: !Ref AlarmEmergencyChangeName
AlarmDescription: A GitHub PR emergency change was merged
MetricName: GitHubEmergencyChange
Namespace: GitHubAuditing
Statistic: Sum
Period: 300
EvaluationPeriods: 1
Threshold: 1
TreatMissingData: notBreaching
AlarmActions:
- !Ref AlarmSNSTopicArn
ComparisonOperator: GreaterThanOrEqualToThreshold
EmergencyChangeFilter:
Type: AWS::Logs::MetricFilter
Properties:
LogGroupName: !Ref LambdaLogGroup
FilterPattern: |-
"is non-compliant!"
MetricTransformations:
- MetricValue: "1"
MetricNamespace: GitHubAuditing
MetricName: GitHubEmergencyChange
We consider this type of alarm to be an “Emergency Change”. It matches the text “is non-compliant!” which is configured as a MetricFilter. These alarms then get sent to the configured AWS SNS topic, allowing for our operations team to be notified in a timely manner.
More Advanced Auditing
If you’re lucky enough to have a subscription to Github Enterprise, there are additional methods for auditing changes such as querying GitHub’s Audit Log API. There are good examples in The GitHub Enterprise Audit log API for GraphQL beginners. This enables a far more granular approach to auditing, allowing for many other types of actions to be monitored as well.
Wrapping Up
SOC 2 compliance is all about checks and balances. As a fast-growing c quickly and continuously deploy code changes. But we need to balance that with the requirement for being able to audit when changes do not follow the usual PR review process. Rather than asking users to track these, we have created automated tooling to ensure we are following our own change management procedure.
Want to solve problems like this, with experts like these? Want to get paid at the same time? Check out Rewind’s open positions and discover a career in data science, engineering, or security.
 Dave Gallant">
Dave Gallant">


