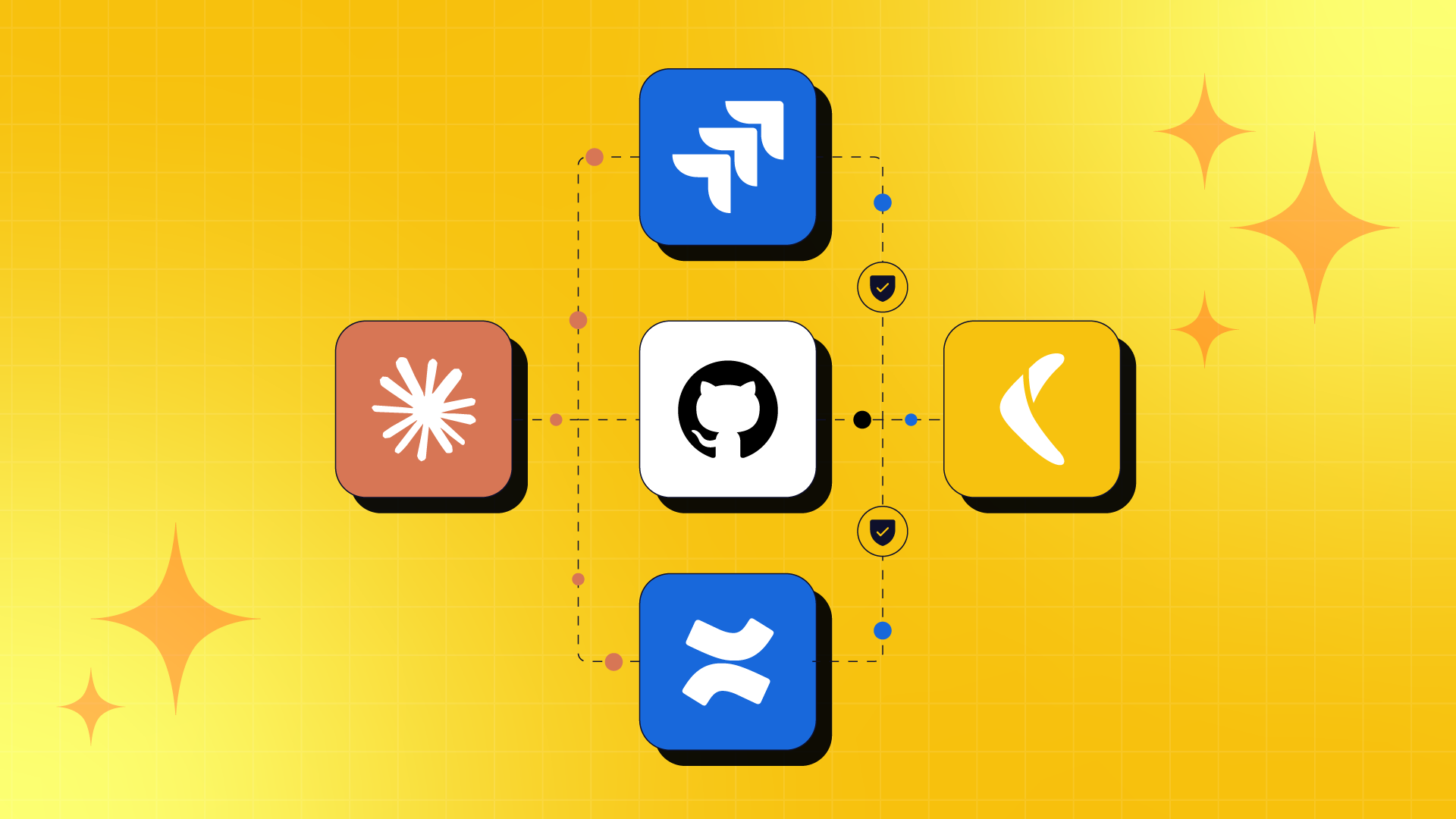
Picture the workflow: a developer opens Claude Code, connects it to an Atlassian MCP integration, and starts a session. From that single interface, the agent has access to GitHub repositories, Jira projects, and Confluence spaces simultaneously. The developer asks it to review a pull request, update the related epic in Jira, and document the change in Confluence.
The agent does all three. In seconds.
Now picture the same workflow, but the agent misreads the scope of the request. It closes Jira tickets that should stay open, overwrites a Confluence page that another team was actively editing, and flags a PR that was already approved. Three platforms. One instruction. No undo button.
This is the blast radius problem, and it is not theoretical.
What MCP actually means for engineering teams
The Model Context Protocol (MCP) is an integration layer that lets AI agents connect to multiple tools from a single interface. For engineering teams, this is genuinely useful. Instead of switching between GitHub, Jira, and Confluence, a developer can coordinate across all three through one agent in one session.
An engineering leader at a mid-size SaaS company described his setup: Claude Code, connected to an Atlassian MCP integration, giving one agent access to Jira and Confluence alongside his code repositories. He called out specifically why he moved to this setup: “Claude Code has everything centralized. Because I can connect it to multiple integrations.”
Centralization is the value proposition. It is also the risk profile.
The blast radius is a feature of connectivity
Traditional tools have bounded blast radii. A change in GitHub stays in GitHub until someone deliberately syncs it elsewhere. A Jira update does not automatically propagate to Confluence or to a codebase. Human engineers are the connective tissue between systems, and human speed limits how fast a mistake can spread.
AI agents connected via MCP eliminate that boundary. One agent with access to three platforms does not just have three times the access of an agent in one platform. It has access to the relationships between platforms: the way a Jira epic maps to a set of pull requests, the way a Confluence page reflects the state of a feature branch, the way a GitHub repo’s documentation needs to stay in sync with the tickets it resolves.
A mistake that touches those relationships does not stay in one system. It propagates across all of them, at the same speed as the original action.
Why containment strategies fall short
The standard response to blast radius risk is scope restriction: limit what the agent can access, require approval before it touches certain systems, segment access so a mistake in one platform cannot reach another.
These strategies work, up to a point. The same restrictions that bound the blast radius also bound the productivity gain. An agent that cannot update Jira and Confluence alongside GitHub is not the centralized workflow tool that made the case for adoption in the first place. It is a faster version of the siloed tools teams already had.
There is a more fundamental problem as well. Restricting scope reduces the probability of a cross-platform mistake. It does not reduce the impact of one when it happens, and it does nothing after the fact. If an agent with restricted access still manages to corrupt data across two platforms, scope restriction does not help with recovery.
What cross-platform recovery actually requires
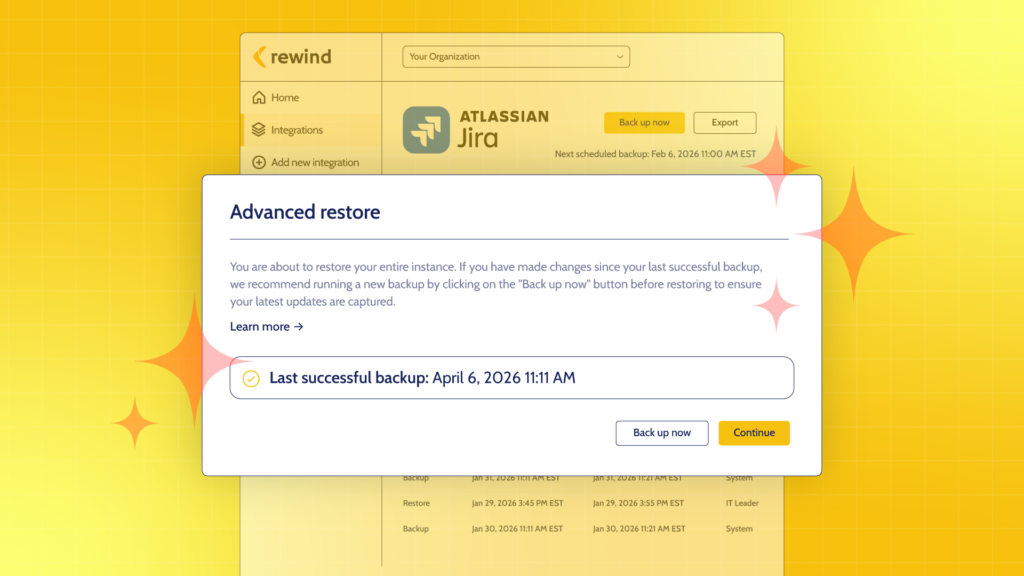
Recovering from a blast radius event is not the same as recovering from a single-platform mistake. Restoring a GitHub repo to its state before an agent acted is a starting point, not a solution, if the Jira tickets and Confluence pages that correspond to that state have also been changed.
Cross-platform recovery requires understanding relationships, not just data. Which tickets mapped to which pull requests. What the Confluence page reflected before it was overwritten. What the synchronized state of three platforms looked like at a specific point in time, before the agent acted.
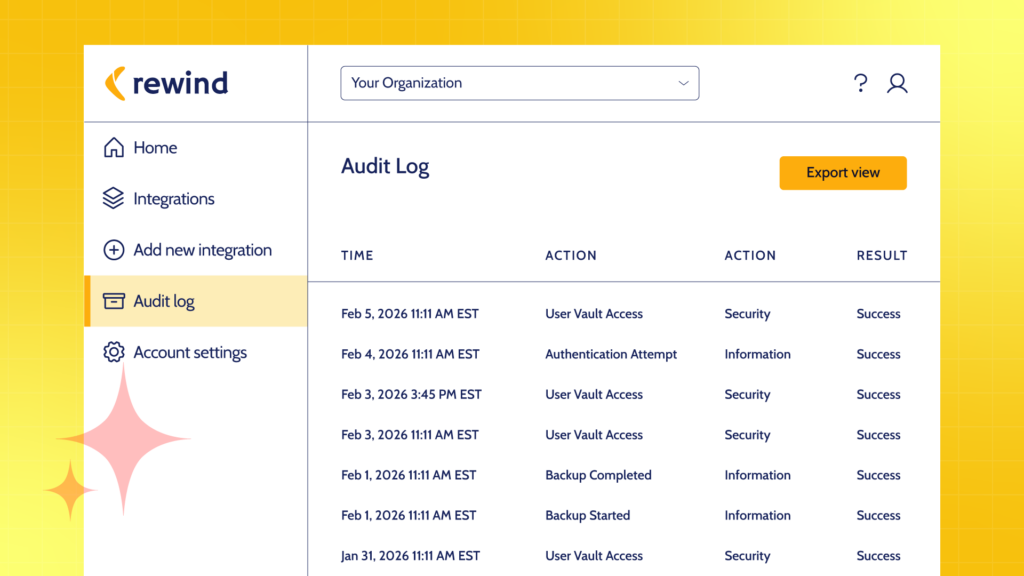
Rewind provides schema-aware, cross-platform point-in-time recovery across Jira, Confluence, and GitHub. When an agent’s blast radius spans multiple platforms, the recovery capability spans the same platforms. The state that existed before the agent acted is always retrievable, across all the systems it touched.
The teams taking full advantage of connectivity
Engineering teams that understand the blast radius problem do not respond by disconnecting their agents from integrated workflows. They respond by building the recovery capability that makes integration survivable.
Connected AI is more productive than siloed AI. Cross-platform agents are more capable than single-platform ones. The blast radius is not a reason to reduce connectivity. It is a reason to make sure that when something goes wrong across platforms, the recovery is just as broad as the mistake.
That is what it means to take the limits off. Not less connectivity. Connectivity with a safety net that matches its scope.
Rewind provides schema-aware, cross-platform backup and point-in-time recovery for the SaaS tools engineering teams depend on, including Jira, Confluence, and GitHub. More than 25,000 organizations worldwide trust Rewind to keep their teams shipping.