
As part of backing up numerous SaaS applications, Rewind has a lot of data stored in Amazon S3 storage. As of writing, that consists of around 3 PB spread over 80 billion objects. By far, S3 represents our single largest line item on our AWS bill. With S3 being such a large percentage of our bill, any cost savings can yield a big result due to the large amount of data and objects stored.
Recently, we undertook a project to look at changing how we tier data within S3. This post will seek to give an overview of what we were doing, the changes we made and the cost savings we yielded. It should be noted that every use case is different and what generated a large saving for us may not in your use case so ensure you run the numbers with your own use case. With the caveats out of the way, let’s dive in!
S3 tiering 101
For those not familiar with tiering of data in S3, you have the opportunity to move data to varying tiers of storage that have different cost profiles. For example, you may start with all data in S3 standard storage which has the highest storage cost but a low access cost. From there, you may decide after 90 days to move data to S3 Infrequent Access (S3-IA) which has a much lower storage cost but a bigger cost in terms of access requests. After 180 days, you may decide to move content to S3 Glacier Deep Archive which has a very low storage cost but a high retrieval cost in terms of time. Finally, after a year you may decide to delete the content entirely.
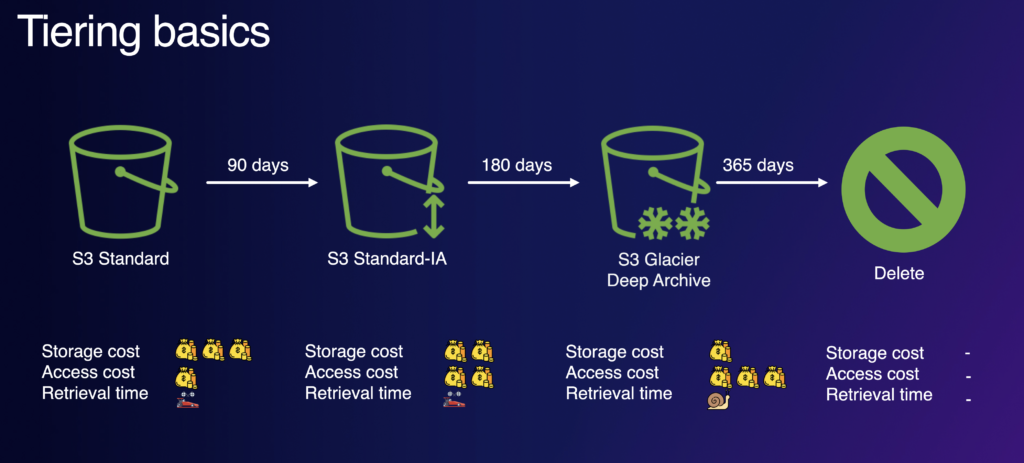
Tiering of data in S3 is facilitated via the use of Lifecycle Rules. These allow you to configure tiering rules and move data at the time periods you choose. S3 also has an option called S3 Intelligent Tiering which will automatically move content between storage tiers based on its access patterns.
As with anything, there’s a cost involved in tiering data. Generally:
- There’s a charge per object to move data to a different tier.
- If you utilize S3 Intelligent Tiering, there’s a per-object monitoring fee to determine which tier data should reside in.
Tiering at Rewind
As a backup application, tiering data fits well at Rewind due to the typical accessibility pattern for data we have stored. We’ve all deleted some data by mistake or had a data loss situation and generally, users notice this quickly and restore from a backup quite quickly. As well as tiering data for best storage cost, we also need to remove data on a schedule. Rewind keeps the current version of an item for as long as you are a customer and all subsequent versions for 365 days.
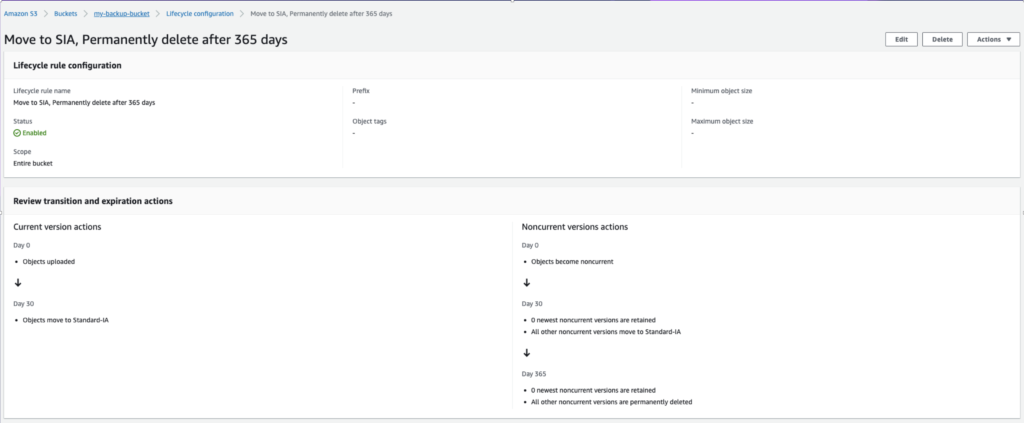
For us, this gives us an S3 lifecycle rule that looks like this:
It’s quite straightforward but let’s walk through it:
- For the current version of objects, they are transitioned to Standard-Infrequent Access (Standard-IA or SIA) 30 days after we back them up. This allows us to save money on storage costs and access costs since most restores are done within the first 30 days. Recall that Standard-IA is less expensive for storage but more expensive for access than Standard
- For the previous version of objects, it’s the same transition to Standard-IA after 30 days but then the additional transition to delete the content after 365 days.
This has proven to be very effective over the years and gives us a storage profile that looks like this:
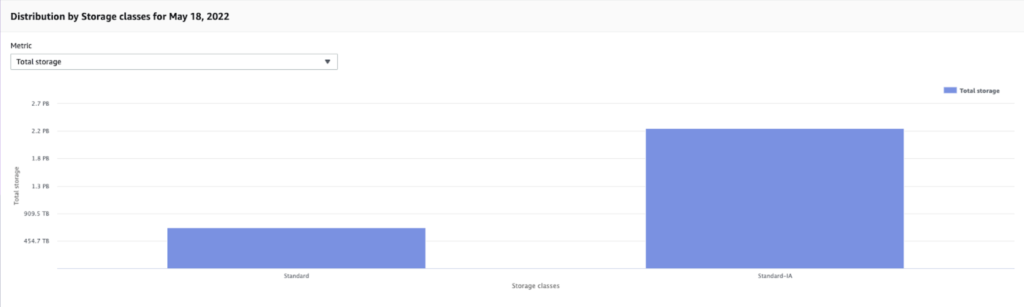
Most of the content is stored in the Standard-IA tier at the lowest cost. Looking at our bill, our total retrieval cost for the Standard-IA tier is approx $0.20/month – a win-win!
Why not intelligent tiering?
Earlier, we mentioned that AWS also offers the S3 Intelligent Tiering class of storage where objects are automatically moved between tiers based on their access patterns. This service comes at a cost, however – the monitoring fee is $0.0025 per 1,000 objects. That is an incredibly low cost and seems to be the way to go.
Not so fast. At Rewind, we have around 80 billion objects in S3 that we have backed up. If we were to use S3 Intelligent Tiering on these objects, that would be around $200,000 per month just for the monitoring! This highlights one of the big things to watch out for with any cloud cost – the multiplier effect. Even very small amounts (like this fraction of a penny here) can result in very large billing impacts with a large data set. Always run the numbers for your specific use case before enabling any option on a large data set.
Glacier Instant Retrieval
Recently, we have evaluated and implemented a switch from S3 Standard Infrequent Access (S3 Standard-IA) to S4 Glacier Instant Retrieval (S3-GIR) as our secondary storage tier. After spending quite some time modeling what the cost profile would look like, it’s best summed up with this small comparison table between S3-GIR and S3-SIA:
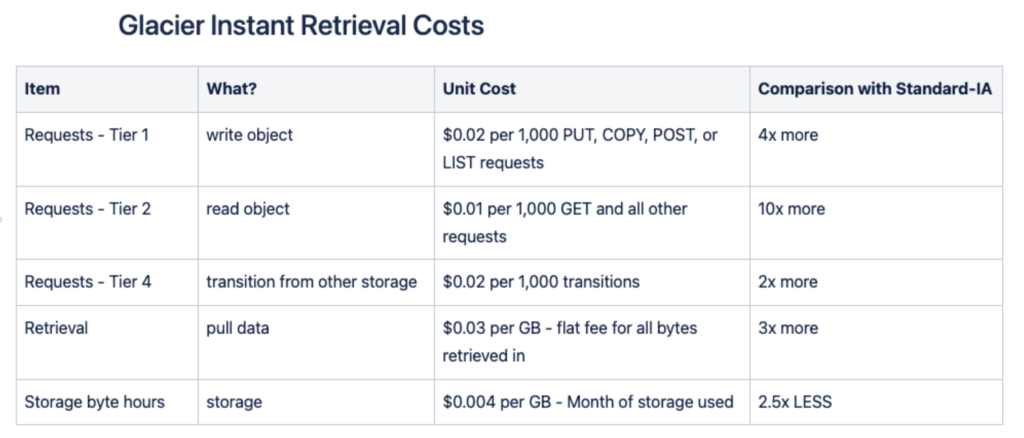
S3-GIR is more expensive (significantly more expensive in the case of reads!) than S3-SIA but 2.5 times less expensive in the case of storage. There could be significant savings here. Let’s look at the numbers:
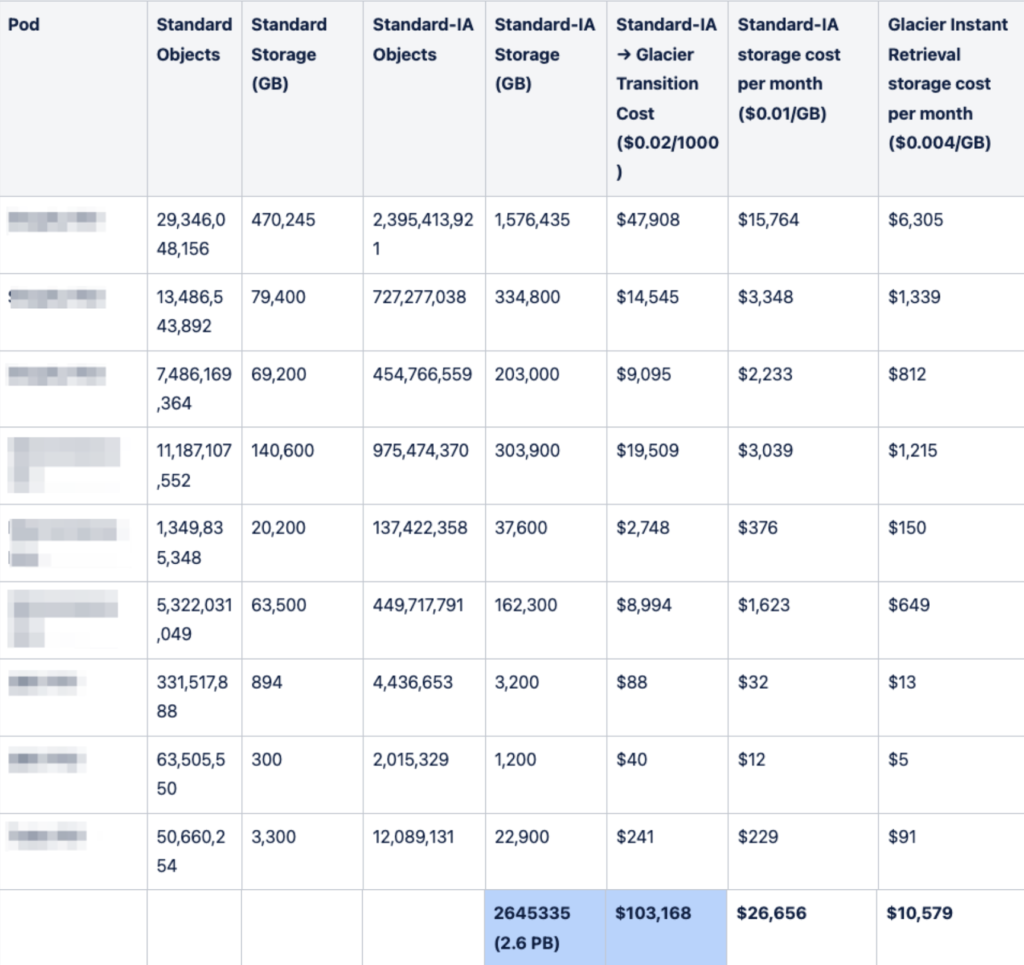
In our case, the difference between using S3-SIA and S3-GIR works out to a savings of around $16,000 per month – wow! That includes all of the storage and access costs so there’s a big savings to be had. However (there’s always a however!), there is a cost to migrate the content from S3-SIA to S3-GIR that works out to $103,000. This is no small amount but with a savings of around $16k per month, we can achieve a payback period of just over 6 months before we start achieving straight savings. We decided to go ahead with the migration and amortize the migration costs over the 6 months.
One gotcha with S3-GIR storage is the minimum storage duration of 90 days. This means content must be stored in S3-GIR for a minimum of 90 days or you are charged an early deletion fee equivalent to the storage costs for the time difference. For example, if you store content in S3-GIR for 31 days and then delete it, you are billed up front for 59 days of storage when you delete the content.
The migration
The migration was incredibly easy and goes to show just how easy it is to run up a large cost with a small change. We changed our S3 lifecycle rule to change the storage class to Glacier Instant Retrieval and set the transition time to 90 days so we do not incur early deletion charges. While this means content will sit in S3 Standard for longer, the cost savings of Glacier Instant more than make up for this.
AWS Cost Explorer is a great tool to show us how this all happened. First, here’s the migration itself:
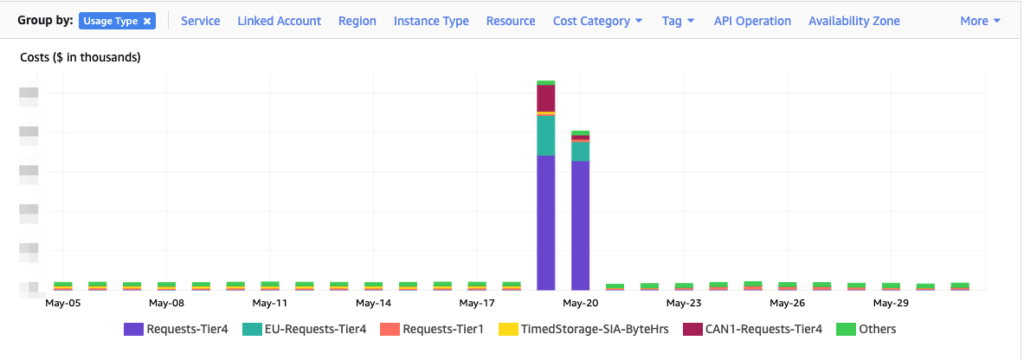
It took the lifecycle rule in the backend around 2 days to transition all of the eligible content from S3-SIA to S3-GIA. Not bad considering that consists of 10’s of billions of small objects!
Now, we can look at how this is working out over a few days. Again, looking at Cost Explorer:
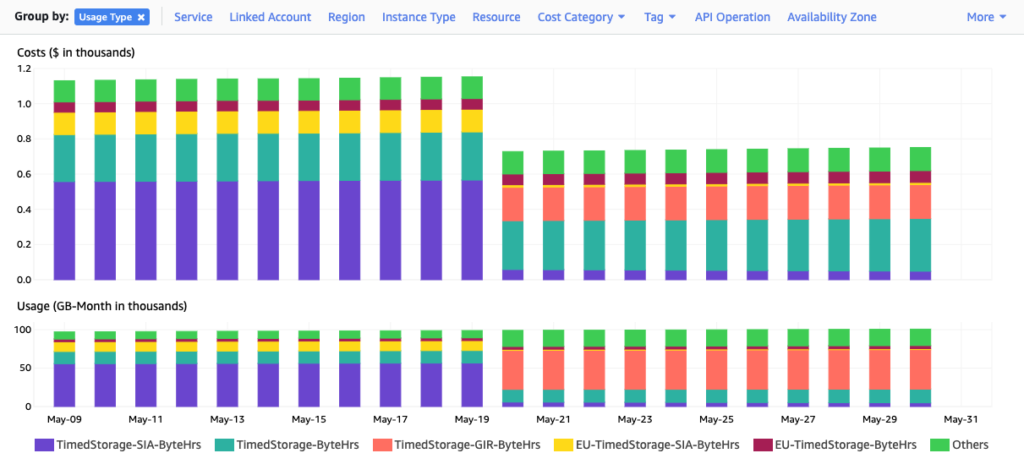
This chart is showing us our cost and our storage usage by day. The step where we migrated on May 19/20 is pretty clear but it’s also very clear that while our storage use stayed the same (lower chart), our overall S3 cost dropped by 35%! We call this “great success”!
Unintended consequences
While almost everything worked out as we had modeled, there was one unintended consequence – we are facing some early delete charges.
Why? Early delete charges are assessed from the time the content was moved into Glacier Instant Retrieval, NOT from the time it was first stored in S3. Our lifecycle rule is removing content that has been present for 365 days and it’s a rolling window so some of the content we migrated is just eligible to be removed. Checking the bill, this is costing us around $100 per month which is a) insignificant and b) will only be a factor for at most 90 days.
Wrap up
There’s a few good lessons to take on board from this process:
- Try and keep an eye on new AWS services or service enhancements. Even if you don’t need it now, it may come in handy for future projects. In this case, Glacier Instant Retrieval was released in December 2021 and when a project came up to review our bill, it was there in the back of my mind as I’d read about it earlier in 2022.
- Model YOUR data patterns with any new service or change. Something that costs $0.0025 per 1000 objects sounds incredibly inexpensive – there’s no way that could cost thousands per month, right? Wrong. When dealing with large volumes of data (80+ billion objects in this case) or large execution counts in the case of services like AWS Lambda, the multiplier effect can be big. Spend the time and model your specific situation.
- Get AWS to do the heavy lifting for you as much as possible. This applies here with S3 lifecycle rules which we used to do the re-tiering but also tools like S3 Batch Operations can be utilized along with tagging to operate on large volumes of data very efficiently.
If you’re interested in solving more problems like this, you should check out Rewind’s open positions to start your career in DevOps, Security, Engineering, and more.
 Dave North">
Dave North">


