Ask most engineering leaders if they have a disaster recovery plan for Jira. Most will say yes.
Ask them what their Recovery Time Objective is. Many will give you a number.
Ask them when they last tested it. That is where the conversation gets uncomfortable.
A documented RTO is a belief. A tested RTO is a fact. For most organizations running Jira today, those two numbers are not the same, and the gap between them is where incidents become crises.
The assumption hiding in plain sight
When organizations say they have a backup strategy, they usually mean that a copy of their data exists somewhere.
But that doesn’t tell you how long it takes to get back to work.
Backup and RTO are related but distinct. Backup is about data survival. RTO is about operational recovery. Having a backup means you will not lose your data permanently. It does not mean you will recover within the timeframe your business requires.
For many organizations, this distinction only becomes visible during an actual incident. And that is the worst time to find out.
The gap is wider than you think
69% of organizations say they require Jira recovery within one to four hours. Even with this expectation, 50% of these organizations have no solution in place to ensure they meet that RTO.
The reality for large Jira instances is different. Full instance restores for organizations with millions of Jira items can take days or even weeks. For some of our customers with tens of millions of items, we measured 27 days or more.
That is not a recovery incident. That is a month of engineering standstill. Delivery timelines collapse. Compliance obligations become impossible to meet. The cost of downtime, documented at roughly $9,000 per minute for enterprise organizations, accumulates in the background while the restore runs.
The expectation is hours. The reality can be weeks. That gap exists in organizations that believe they are prepared, because they have never actually had to test the assumption.
Why RTO became the defining metric
For most of the last decade, backup was the right priority. The primary risk was permanent data loss: accidental deletion, a corrupted file, a failed migration with no rollback. Backup addressed that problem. The goal was to make sure the data could be recovered from somewhere.
AI changed the risk profile.
When AI agents operate at machine speed with write access to production Jira environments, data disasters happen faster and at larger scale than human operators ever created. A single agent can propagate a mistake across thousands of records all before anyone even notices. The damage is not the loss of a few items. It is the corruption of an entire environment.
At that scale, the question is no longer whether you can recover the data. It is how fast you can get your team back to work. The answer to that question? It’s your RTO.
Backup answers the question of whether your data survives. RTO answers the question of whether your business does.
What a credible RTO requires
A credible RTO is not a number you write in a DR document. It is an operational commitment backed by infrastructure that can actually deliver on it.
For routine incidents, granular restore and point-in-time recovery deliver fast RTOs. Operations like recovering a specific item, a specific version, or a specific set of records are fast when the tooling is designed for them. Rewind has provided this capability for years.
For large-scale disasters where the production instance is corrupted or unusable and recovery requires restoring the environment rather than specific records, a different approach is required. The restore time for a full Jira instance scales with instance size. No amount of optimization speeds up a 50-million-item restore.
The only way to achieve a near-zero RTO for a major data disaster is to have an operational environment ready to switch to before the disaster happens.
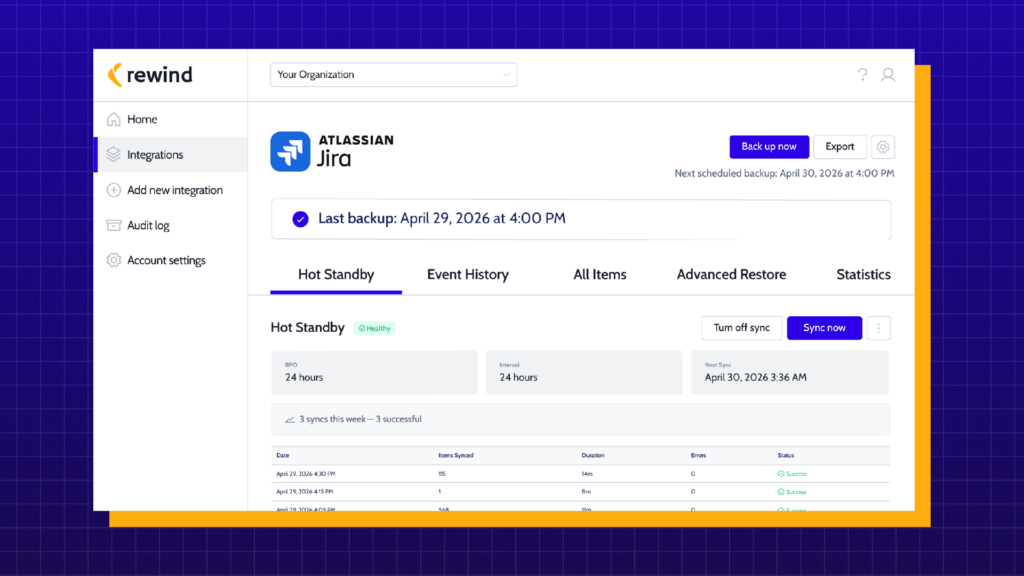
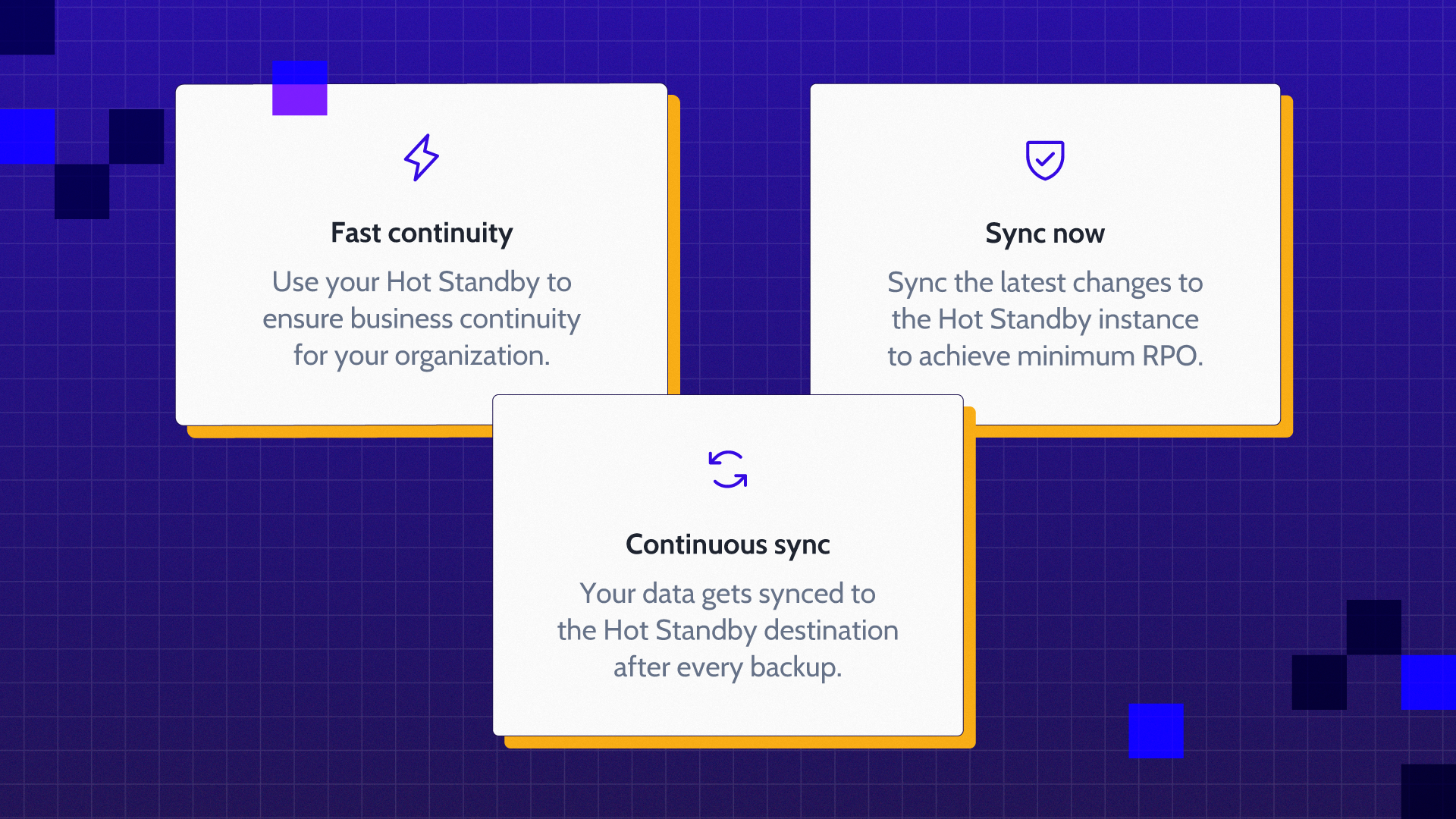
That is exactly why we created Hot Standby. It’s a continuously synced, secondary Jira instance in a separate region that runs in parallel to your production instance. Always on, always ready. When a disaster strikes, your team can choose to fail over in minutes. The data gap since the last sync is closed. The maximum RPO is 24 hours. Your team is back in business.
Near-zero RTO is not a marketing claim. It is a description of how the architecture works: the standby instance is already running, already synced, and already in a production-like state. The time to recover is the time to make and communicate the decision, not the time to run a restore.
The question worth asking today
You do not need to wait for an incident to find out what your RTO actually is.
How large is your Jira instance? How long would a full restore take at that scale? Is there infrastructure in place to fail over to a known-good state if the production instance becomes unusable?
If you cannot answer those questions with confidence, your RTO is an assumption. And assumptions have a way of being tested at the worst possible time.
Hot Standby for Jira is available now on Rewind’s Advanced plan. Talk to a resilience expert to understand what your real RTO looks like.
Sources:
– Rewind SaaS Resilience Report, Q4 2025: 69% require recovery within 1-4 hours; 73% say Jira outages impact delivery timelines
– Rewind Q1 2026 research: full instance restore times for large Jira instances
– Splunk, Hidden Costs of Downtime: $9,000 per minute for enterprise organization
 Randa Fadly">
Randa Fadly">