
For most of my career, the expensive part of shipping code was writing it. Review was the cheap step at the end: a colleague glances at your diff, nods, and you merge. That arrangement quietly assumed something that is no longer true: that humans write code roughly as fast as humans can review it.
Agentic development broke that assumption. Over the last year, the cost of producing a correct-looking pull request has collapsed. An engineer with a coding agent can open three, five, ten PRs in a day. The writing got cheap. The review did not. Our merge throughput is now gated almost entirely by how fast humans can read each other’s diffs, and human attention is the one input that doesn’t scale with better models.
We were merging on the order of forty PRs a day across our GitHub organizations, well over a thousand a month, and climbing. And every one of those PRs—a typo fix, a dependency bump, a config tweak, a change to our multi-tenant isolation boundary—competed for exactly the same scarce resource: a senior engineer’s focused attention. That is a terrible allocation. The typo fix doesn’t need a principal engineer. The tenant-isolation change needs more than one.
So we built a system that fixes the allocation. It’s called Diff Vader: an AI reviewer that looks at every PR across our orgs and, for a carefully bounded set of low-risk changes, becomes the only reviewer needed, freeing human reviewers to spend their judgment where judgment actually matters. Behind it sits a backend we call the Death Star, which is where the safety, measurement, and compliance story lives.
This post is about how it works, and (more importantly for anyone considering this) the parts that the “we let AI approve our PRs” headline tends to skip: how you make it safe, how you prove it’s safe, and how you bring your compliance function along instead of around.
We didn’t invent this
Two companies published the playbook before us, and it would be dishonest not to start there.
Intercom’s Fin team wrote about letting AI approve their pull requests. The headline numbers are striking: more than 19% of their PRs are auto-approved with no human reviewer, and AI-authored code reverting roughly ten times less often than human-authored code (0.53% vs 5.39% on the backend). But the line that stuck with me was their reframing of the safety argument: “speed is not the enemy of safety. It’s a prerequisite for it.” Their point, backed by the uncomfortable observation that every one of their past outages had been on a human-approved change, is that human review is not inherently safe. It feels safe. A reviewer who doesn’t have the time or attention to actually trace a change is a rubber stamp wearing the costume of a control.
Rootly wrote about killing their small-PR rule. Their teams had a cultural norm: keep PRs small, stack them, make them easy to review. Sensible advice optimized for how humans write code. But, as they put it, “AI agents don’t work that way. They think in features.” Forcing an agent’s coherent, interconnected change into artificially small slices made review harder, not safer. Rootly’s response was to stop grading PRs by size and start grading them by risk, blast radius, and revertibility, and to move the real safety boundary from merge-time to rollout-time with feature flags. They also named the thing AI reviewers actually need to catch: not syntax, but context bugs: “the code works, but it’s applied to the wrong thing.”
We took the core thesis from both, which is decompose review into specialists, grade by risk not size, and invest in being able to undo things, and built on it with three things specific to us:
- Reviewers that know our domain. We run a multi-tenant SaaS that backs up customers’ most critical data. A generic “security” reviewer doesn’t know what cross-tenant data leakage looks like in our codebase, or what makes a restore idempotent, or why a retention-policy change is irreversible in a way a feature change isn’t. Ours do.
- A deterministic verdict engine. The AI produces findings. A small, unit-tested, boringly deterministic piece of code turns those findings into the decision. The judgment is AI; the gate is not a vibe.
- A policy hand-audited against our actual repos. Not a template. Every repo in scope was looked at by a human who decided which paths can never be auto-approved and how large a change can be before it needs human eyes.
The reframe that makes the whole thing work: risk is not size
The single most important idea in Diff Vader is also the simplest, and it’s the one Rootly handed us: a PR’s risk has almost nothing to do with its line count.
A twelve-line database migration that adds an index to a fifty-million-row table is one of the most dangerous things you can ship because it can lock the table and take production down. A three-thousand-line PR that regenerates an API client from an updated schema is, in risk terms, nothing. If you gate review on diff size (“small PRs get a light touch, big ones get scrutiny”) you have built a control that is wrong in both directions. It waves through the dangerous small change and burns reviewer hours on the safe big one.
So Diff Vader grades every PR with a risk label — 🟢 LOW / 🟡 MEDIUM / 🔴 HIGH — and that grade is derived from what the review found, not from how many lines changed. A finding from one of our high-blast-radius reviewers (a locking migration, an IAM scope widening, a change to a tenant boundary) escalates a PR to HIGH no matter how few lines it touches. Size shows up exactly once, and not as a risk signal: there’s an upper limit (around ten thousand lines) past which we don’t ask the AI to review at all, not because a big diff is risky, but because no reviewer, human or machine, can usefully hold that much change in their head at once. That’s a human-attention limit, and we’re explicit that it’s separate from the risk grade.
The council: many specialists, one question
The instinct when you reach for an AI reviewer is to write one big prompt: “review this PR for bugs, security, performance, and style.” That produces a mediocre generalist that does everything a little and nothing well.
Instead, Diff Vader runs a council of a dozen-plus specialist reviewers, each examining the diff through one lens, all in parallel. There’s a correctness reviewer, a security-and-tenant-isolation reviewer, a test-adequacy reviewer (“do these tests actually assert the new behavior, or just import it?”), a blast-radius reviewer, a revertibility reviewer, a performance reviewer, a supportability reviewer (“if this breaks at 3 AM, can on-call diagnose it from the logs alone?”), reviewers for infrastructure-as-code, for database migrations, for GitHub Actions workflows, for supply-chain risk in dependency changes, and domain-specific ones like backup-correctness that only run on the relevant repos. Each one auto-skips when the diff has nothing for it to look at.
Every reviewer, no matter its specialty, is pointed at the same underlying question:
If this is wrong in production, what user-facing behavior breaks?
That question does a lot of work. It rules in the things that matter and rules out the thing that makes most automated review unbearable: bikeshedding. Diff Vader is explicitly forbidden from flagging “this doesn’t match our naming convention” or “I’d add a comment here.” Nobody’s time (human or AI) is well spent on that, and a reviewer that cries wolf about style gets ignored when it has something real to say.
The specialists produce findings, each with a severity and a confidence score. Then a separate, deterministic verdict engine (ordinary, unit-tested code, not a model) turns those findings into a decision: the risk label, and whether the PR is eligible to be approved by the bot alone. Keeping the judgment (AI) and the gate (deterministic code) separate is what lets us reason about the system’s behavior, test it, and explain it to an auditor. “Why did this PR auto-approve?” has an answer you can read in a config file and a few hundred lines of TypeScript, not an answer that lives inside a model’s weights.
That config file has a name and is worth pausing on. The policy file is a single piece of YAML, CODEOWNERS-protected, that ships through the same PR review as any other code change. It declares the hard rules the verdict engine is not allowed to override no matter what the council says: paths that touch authentication, authorization, secrets, encryption, and anything that changes who is allowed to approve future changes always require a human. The judgment can be brilliant or dumb; on those paths it doesn’t get to drive.
Writing that policy was its own piece of work, and the part of this project I’d most quietly recommend to anyone else doing it. Every repo has a different danger surface because what’s safe in a generated-client library is not safe in the service that handles customer credentials, so we couldn’t ship a template. We used the AI itself to do the first pass: scan every repo, surface every path that smelled like a tenant boundary or a credential or an IaC lifecycle change, and propose a per-repo “always require a human” list. Humans then audited each proposal repo by repo, kept what fit, threw out what didn’t, and added the things the model missed. There’s a satisfying recursion to it: the bot helped author the rules it isn’t allowed to overrule.
One more deliberate choice: a second AI vendor (GitHub Copilot) reviews alongside the council, but as advisory only. Its findings are surfaced to the engineer and feed our calibration data, but they never gate the verdict. We tried making it a required cross-check and found it was soft-blocking good auto-approvals on “I couldn’t review this PR” boilerplate: a calibration burden with no safety benefit. A second opinion is useful context; it shouldn’t be a veto you can’t reason about.
What an engineer actually sees
Diff Vader posts on the PR as diff-vader[bot], using exactly the same GitHub primitives a human reviewer uses: a formal Review (Approve / Request changes / Comment), inline comments anchored to the relevant lines, and a summary. There’s nothing exotic for engineers to learn; the AI reviewer shows up in the reviews tab like any colleague would.
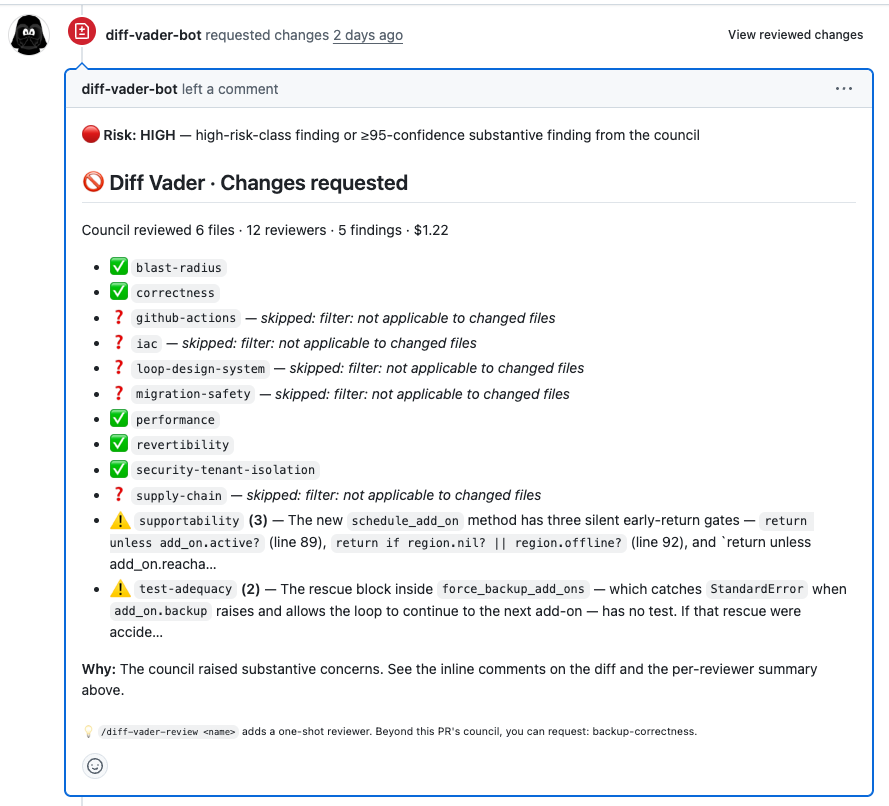
At the top is the risk banner. Below it, the per-reviewer breakdown: which specialists fired, what they found, at what confidence, and which ones skipped because the diff didn’t touch their area. Each substantive finding also lands as an inline comment at the exact line it’s about. The engineer addresses it the way they’d address any reviewer: push a fix, or reply on the thread to explain why it’s a non-issue (the bot reads the conversation and won’t re-raise a point you’ve resolved).
When you push that fix, Diff Vader doesn’t re-scan the entire diff from scratch. By default it runs in verifier mode, where it checks whether the prior findings are now resolved, and that’s it. That keeps a re-review roughly ten times cheaper than a full one, and more importantly, it stops the bot from spinning up a “review loop” where every push surfaces a fresh batch of things to argue about. If you’ve meaningfully reworked the diff and do want a full council pass, /diff-vader-review –fresh on the PR forces one. Most pushes are addressing prior findings, not introducing new ones; the default should match that reality.
Three things we’re careful to say out loud:
- Auto-approve is not auto-merge. When Diff Vader approves, it posts an APPROVE review, the same thing a human reviewer clicking “approve” does. It does not push the merge button. The engineer merges (or GitHub’s native auto-merge does, if they enabled it), and every existing gate—CI, branch protection, required-reviewer counts—still applies. The bot is one input to those gates, never a replacement for them.
- “Changes requested” is not “needs a human.” When the council fires on a substantive finding, the bot’s verdict is REQUEST_CHANGES: the same primitive a human reviewer would use to say “fix this and I’ll re-review.” It does not escalate the PR to a human approver; the bot just wants the fix and another pass. Only the distinct NEEDS_HUMAN verdict (high-risk paths, over-cap diffs, the explicit /request-jedi-review override) routes a PR to a human reviewer.
- A human is always one command away. Commenting /request-jedi-review on any PR forces a human reviewer and stands the bot down from the auto-approve path. The override is a feature of the toolchain, not a line in a policy doc.
And because the whole council is packaged as a plugin to Claude Code, engineers can run it locally before they even push. /diff-vader-review in their editor runs the same reviewers with the same rules in about two minutes, so findings get caught before they cost a CI cycle.
The Death Star: the part nobody clicks but everything runs through
A bot that posts reviews is the visible 10%. The other 90% (the part that lets me stand in front of our leadership and our auditors and say “this is working” with evidence instead of optimism) is the backend. We call it the Death Star.
It does five things that matter:
It measures everything. Every PR the bot touches is recorded: the verdict, the risk grade, the findings, the cost, time-to-first-review, time-to-merge: all of it compared against a historical baseline from before the bot existed. This is the “data, not vibes” engine. When someone asks “is this actually helping or are we just excited about it?”, the answer is a dashboard.
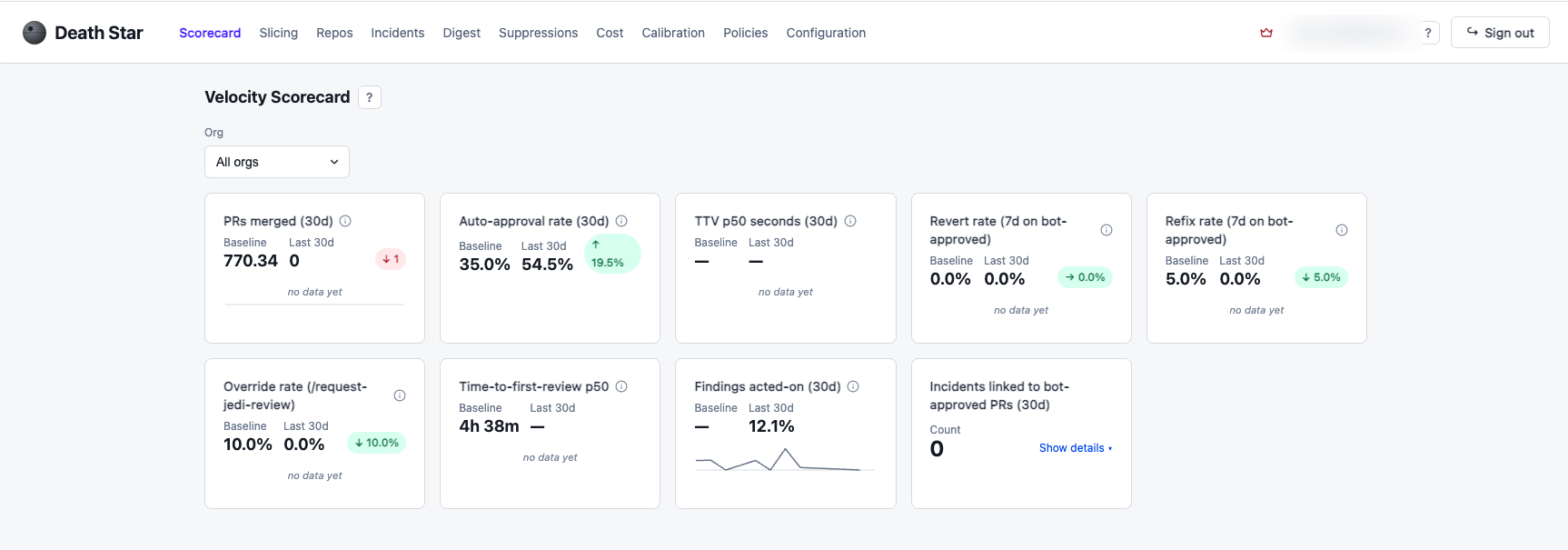
It keeps an audit trail. Every AI verdict is logged, attributable, and queryable per-PR in the same evidence shape an auditor would expect from a human-approved change. Pulling “every PR the bot approved this quarter, with full detail” is a single query.
It links incidents back to verdicts. The Death Star is wired into our status page and our post-mortems repository. Whenever an incident is declared or a post-mortem is filed that references a PR, the dashboard automatically flags whether that PR was AI-approved and surfaces the original verdict for the write-up. We want to know, loudly and immediately, if the bot ever waves through something that bites us. (So far, that count is zero.)
It shows what it costs. Token spend per review, per repo, per day, against a configurable ceiling. For the curious: reviews average around $0.73 per PR, with significant variance. Small dependency bumps cost cents; large multi-file PRs with many substantive findings can push past twelve dollars. We knew the shape of that distribution before we wrote a line of the integration. We used AI to do the modeling the same way we drafted the policy file: by running thousands of historical PRs through a simulated council, project per-PR cost and total monthly spend, and deciding whether the program was worth building before paying for a single real review. The projection came back at roughly that $0.73 average, and the live data so far is tracking it. The whole program ends up costing a rounding error against the engineering hours it gives back. The gating constraint on this project was never spend. It was safety.
And it runs the loop that makes the bot better. This is my favourite part, because it’s where the humans stay in charge.
How the bot gets better: a feedback loop that includes humans
A static AI reviewer decays. Prompts that were well-calibrated at launch drift as the codebase and the models change. So we built an improvement loop, and engineers are in it whether they think about it or not:
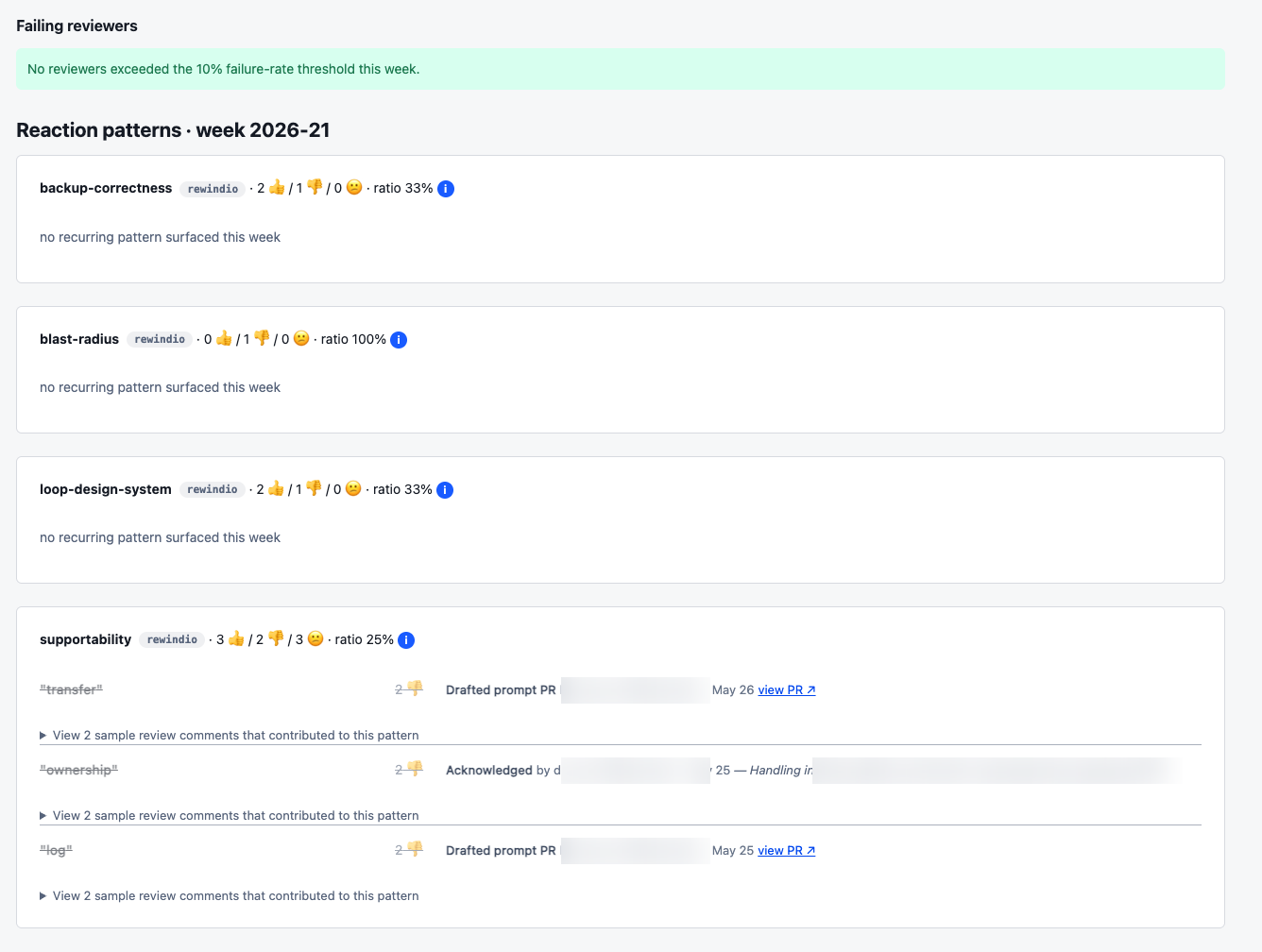
- Engineers react to bot comments with 👍 / 👎 / 🤔 — native GitHub reactions, zero friction. A 👎 on a noisy finding isn’t complaining; it’s signal.
- The Death Star aggregates those reactions into a weekly digest: which findings engineers loved, which they dismissed, where the bot’s confidence was miscalibrated.
- An engineering manager or tech lead on rotation reads the digest (about thirty minutes a week) and decides: keep this pattern, suppress that noisy one, retire a reviewer prompt that isn’t earning its place.
- Each decision becomes an ordinary pull request against the policy or the prompt, reviewed by Diff Vader itself, then by a human, then merged. The bot never edits its own prompts or policy. Every change to how it behaves goes through the same human-reviewed gate as any other code.
- Suppressions auto-expire after 90 days unless someone re-justifies them, so the bot can’t slowly go quiet on a whole class of real problems because of one bad week of reactions.
The point isn’t that the loop is clever. It’s that it keeps a human’s hand on the wheel of a system that would otherwise drift silently. You’re not babysitting a static tool; you’re steering one that’s actively learning, and the steering is governed by the same change-management discipline as your production code.
The part nobody talks about: compliance
Here’s where most “AI is approving our PRs” stories go quiet, and where I think the real work is.
If you operate under SOC 2, ISO 27001, or any serious change-management regime, “an AI approved this production change” is not a sentence you get to say casually. Change management is an audited control. Letting a non-human approve changes, and in some cases be the only approver, is exactly the kind of thing that turns a clean audit into a finding if you can’t show you thought it through.
So before we flipped a single repo to live, we did the unglamorous thing: we brought our GRC lead in at the start, not the end. (Intercom flagged this as the right move, and they were right.) The output was two auditor-facing artifacts that now live alongside the system.
The first is a controls mapping: every relevant control, the specific Diff Vader mechanism that satisfies it, and the evidence an auditor can pull on demand. A few of the load-bearing ones:
- Security-sensitive changes can never be auto-approved. Anything touching authentication, authorization policies, secrets, encryption, infrastructure, or governance files is gated by the policy engine deterministically. It’s a property of the code, not a hope about the model’s judgment. (ISO 27001 A.8.32.3)
- Separation of duties holds. An AI that writes, reviews, and ships its own change with no human checkpoint is not acceptable, and we enforce it in the tooling: a PR authored by a non-human (an agent, a bot) can be reviewed by Diff Vader but can never be merged without a human clicking the button. That human becomes the accountable shipping engineer. The bot never both writes and ships alone. (SOC 2 CC8.1.2)
- Every AI-approved PR is labelled and queryable, with a complete evidence trail (the review rationale, the risk grade, the test results, the merge event, and who triggered it) identical in shape to a human-approved change. (SOC 2 CC8.1.3 / ISO 27001 A.8.32.2)
- Human oversight is embedded in the design, with documented override paths that are features of the toolchain. (ISO 42001 Annex A.9.3)
- The system is monitored continuously and reviewed formally every quarter—revert rates of AI- vs human-approved PRs, incidents linked to AI approvals, override usage, and a sampled read of the bot’s comments for drift—and each review is filed and retained as evidence. (ISO 42001 Clause 9.1)
The second artifact is a risk assessment, aka the document ISO 42001 actually requires before you deploy an AI management system. We enumerated thirteen ways the system could fail: the bot approves a flawed PR; the bot approves a malicious PR; its credentials are compromised; a model upgrade quietly regresses its judgment; the suppression list creeps until the bot goes blind to a real problem; the policy file gets tampered with; the council misses a small-but-substantive risk. For each one we rated likelihood and worst-credible impact, documented the mitigations, and recorded the residual risk. All thirteen come out at Low or Minimal after mitigation, on the same risk scale we use for every other risk assessment in the company, and the handful of high-impact ones are explicitly accepted, in writing, with named compensating controls, because each requires several independent safeguards to fail at once.
I’ll be honest about why this section exists in a public blog post: most teams will under-invest here, and it’s the thing that will actually stop you. The engineering is the easy 80%. Being able to hand an auditor a controls mapping and a signed risk assessment, and having engaged your GRC function early enough that they’re co-authors rather than blockers, is the 20% that determines whether this ships or dies in a review meeting. Do that part first.
The numbers, honestly
We’re past the first hurdle. Diff Vader spent its first week in shadow mode, reviewing every PR across our four-hundred-plus repos and posting its verdict, but gating nothing. We used that week the way you’re supposed to: collected calibration data, watched where the bot disagreed with humans, fixed the issues that surfaced. With the risk assessment signed off and the calibration questions answered, we flipped to enabled mode: every repo across some orgs, a curated subset of repos across others. Even with just a week of live data, the value is obvious; we’re now mostly using the feedback loop to iron out edges, not to validate the premise. The design has held up.
The numbers below span the shadow week and the first week of enabled-mode data. Read them as directional (small sample, still expanding), not a final verdict:
- Around 40% of PRs come back as auto-approve, at the top end of the 30–40% band we set as the target. (More on why that number runs hot in a moment.)
- On the PRs the bot approves that also get a human review, humans have agreed with the bot’s call about 99% of the time. Our gate to flip from shadow to live was 90% agreement. We’re well clear of it.
- Zero reverts and zero incidents have been linked to a bot-approved PR.
- The cost works out to well under a dollar per PR on average, tracking the projection.
A word on why that 40% runs hot. A meaningful slice of our PR volume is what we call “gem bumps”: internal Ruby libraries (our backup engine is the largest example) get version-bumped, and every downstream service that depends on them pulls in the new version with a one-line diff. Dozens of small PRs per release, all mechanical, all already exercised against the library’s own test suite long before they reach a consumer. That class of change is exactly where AI-only review is most defensible: the real review happened upstream in the library; the consumer-side PR is just propagation. As we move from the current mix (every repo on some orgs, a subset on others) to full coverage across every org, the mix will shift toward more genuinely novel application code and fewer mechanical bumps, and we expect the deflection rate to settle closer to the middle of the 30–40% band rather than its top. That’s fine. The number we actually care about isn’t the deflection rate at all; it’s the bottom two on that list: bot-approved PRs that should not have been (currently zero) and incidents traced to bot approvals (currently zero). Those are the ones we’ll never round down on.
What success looks like ninety days from full rollout is unchanged: 30–40% of low-risk PRs reviewed by AI alone, a meaningful cut in time-to-first-review, and the numbers that actually matter: zero incidents and zero reverts traceable to a bot-approved merge. The early data is tracking the pre-build projection once you account for the gem-bump skew. For reference, Intercom sits above 19% auto-approval; we designed for higher because our policy is hand-audited per repo and our reviewers know our domain.
If the data ever stops clearing the gates, the rollout stops. The promotion criteria are objective on purpose (agreement rate, incidents, reverts) precisely so that nobody, including me, gets to advance this on enthusiasm.
What I’d tell another engineering leader
If you’re staring at the same wall we were, with agents making code cheap to write, review capacity flat, and your best engineers spending their attention on PRs that don’t need it, here’s the compressed version of what we learned:
- Review is the bottleneck now. Optimize the allocation of human attention, not the speed of human reading. The win isn’t faster reviews; it’s fewer reviews that a human needs to do at all, so the ones they do are the ones that need a brain.
- Grade risk, not size. Diff size is a proxy so bad it’s actively misleading. Let what the review finds drive the grade.
- A council of specialists beats one generalist prompt, and keeping the judgment (AI) separate from the gate (deterministic, testable code) is what makes the whole thing explainable.
- Invest in detection and rollback, not just review. Your safety net is being able to see and undo a bad change, not pretending review will be perfect. Human review never was.
- Bring GRC in on day one. The controls mapping and risk assessment are not paperwork you do at the end. They’re the thing that determines whether this ships at all. Make your compliance function a co-author.
- Build the system to learn, with humans steering. A static reviewer decays. A loop where engineers’ reactions feed human-approved tuning gets better every week, and never edits itself.
- Model effectiveness against your real data before you build. Before we wrote a line of integration code, we used Claude Code to run a simulated council against roughly three thousand historical PRs across our repos, projecting auto-approve rates, where the bot would have disagreed with the humans who actually shipped those changes, and per-PR cost. That single exercise sized the budget, set the deflection target, and told us whether the project was worth doing at all. The same AI you’re planning to deploy is also the best tool you have to predict what it’ll do on your data. Use it twice — once for the modeling, then for the system itself.
- Don’t vibe-code a system this consequential. Diff Vader and the Death Star were built almost entirely with Claude Code, but not by typing “build me an AI reviewer” and shipping whatever came back. We used spec-based development — Superpowers for the core methodology, augmented with our own skills — which forces every piece of work through brainstorm → written spec → reviewed implementation plan → execution → code review, with discrete human checkpoints in between. The model is much faster than you. Without a tight spec at the front, it will happily build the wrong thing at scale, gracefully and with confidence. The spec is the leverage point; treat it that way.
Speed isn’t the enemy of safety. Done right, with the measurement, the audit trail, and the compliance scaffolding underneath, speed is how you get safety, by spending your scarce human judgment on the changes that actually deserve it.
The writing got cheap. It’s time the reviewing caught up.
Diff Vader and the Death Star were built at Rewind. If you’re working on something similar and want to compare notes, I’d genuinely like to hear from you at dave.north@rewind.io.
“Diff Vader” and “the Death Star” are internal nicknames that started as inside jokes and stuck. Neither name is affiliated with, endorsed by, or licensed by Lucasfilm Ltd. or The Walt Disney Company.
 Dave North">
Dave North">


