
A recovery time objective (RTO) is one of the main parameters within a disaster recovery strategy. It defines the maximum length of time your systems can be down before there are negative impacts on your business.
Determining an appropriate RTO for each of your services lets you gauge whether you’re meeting your service level agreements (SLAs) with customers. It also informs whether you’re able to restore service within an acceptable time frame. Regularly breaching your RTOs after incidents is a sign that your disaster preparedness needs more attention.
In this article, you’ll learn why RTOs matter, how they contribute to disaster recovery, and the techniques you can use to progressively improve your objectives.
What are RTOs?
The recovery time objective is the amount of downtime a system is allowed to suffer before it must be successfully restored. When services go offline, you need to recover them quickly to avoid lost sales, reputational damage, and excess support requests from customers. RTOs define how much time you’ve got before negative effects are unavoidable.
Recovery point objectives (RPOs) are an adjacent concept tied to RTOs. Whereas RTO defines the amount of permissible downtime, RPO establishes the extent of permitted data loss that incidents can incur. This is important because not all incidents are necessarily recoverable—what happens if an administrator accidentally deletes your production database?
An RPO of one hour means a catastrophic incident shouldn’t destroy any data that was an hour old when the event started. RPOs are met by implementing a backup regime that replicates critical data on an appropriate cadence. RTOs are achieved by integrating tools and processes that allow incidents to be rapidly detected, investigated, and recovered from, which includes efficient restoration of previously backed up data.
Why RTOs matter
RTOs measure how long data recovery teams have to restore service after a disaster. They focus resolution efforts by providing a consistent objective that everyone works toward. RTOs benefit the organization by allowing all teams to identify when incidents start to materially harm the business.
Customers may expect RTOs in SLAs
RTOs are often a component of Service Level Agreements (SLAs). This customer-facing contract sets out the reliability characteristics your service will exhibit over a particular period.
Overall uptime is often the key constituent of an SLA, but it may also cover other metrics, including RTOs. An SLA that states data will be inaccessible for no longer than an hour contains an implicit RTO of one hour or less, for example.
RTOs balance disaster preparation and cost efficiency
RTOs guide you toward maintaining a balance between disaster preparation and cost efficiency. A low RTO means you’ve committed to rapidly resolving incidents. This means you must be highly prepared for disaster, which usually carries higher ongoing costs. You’re more likely to need a comprehensive tool suite, dedicated teams, and regular rehearsals of possible incidents for the RTO to remain attainable.
Conversely, higher RTOs give you much more leeway when an incident begins, which can represent a lesser state of preparedness. It’s usually less expensive to maintain high RTO values but this needs to be considered alongside the potential costs of incidents.
A high RTO could be more likely to get breached if your disaster preparedness is low and you’re infrequently rehearsing your recoveries. That longer time window will soon be consumed if you’ve not practiced how you’ll utilize it.
RTOs prepare you for disasters and data loss
IT incidents are unavoidable. However proactive you are in fixing bugs and scanning for security threats, sometimes a service will go down and take your data with it. RTOs demonstrate you’re being pragmatic in acknowledging this inevitability.
Estimating how long it’ll take you to recover, making a commitment that service will restore at a given time, and regularly rehearsing your strategy prepares you for when the event occurs. Once you’ve practiced recovering your service within the RTO, you and your customers can be more confident that any unforeseen events won’t have lasting consequences for your business.
Determining RTOs
Determining an RTO requires careful analysis of all your systems. RTOs must be realistic to be effective. You can’t simply choose a number, write it into your SLA, and hope for the best when an outage occurs.
The process of determining an RTO can be summarized as follows:
- Assess the criticality of each service. High-priority services need a lower RTO so they’re restored more quickly.
- Measure your actual recovery time. Check how quickly backups can be utilized. RTOs are meaningless if it’s technically impossible to recover from a worst-case scenario in the allotted time. Don’t underestimate how long it can take to rebuild services using full backups.
- Attempt to improve your RTOs. After establishing a baseline figure, you can try to lower your RTO by adjusting your disaster recovery tools and strategies. You’ll see how to do this in the next section.
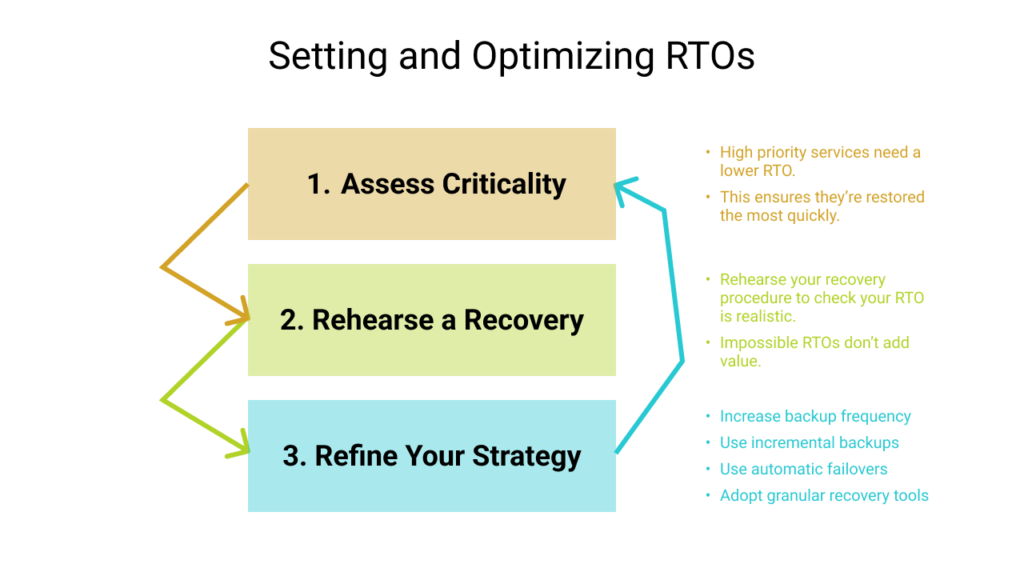
To start deciding your RTOs, look at the required quality level for each of your services. Ask yourself how long your business or product could function in their absence. Individual services can be allocated their own RTOs to reflect their level of criticality. A payment system might be given a lower RTO (shorter recovery window) than a photo upload service, for example, because failed payments will immediately affect your bottom line.
Next, you need to calculate whether the RTO you’ve arrived at is actually achievable. The assessment should be based on data such as the time it took you to restore after the last incident. Refine this value by rehearsing your disaster recovery strategy.
Often there are technical limitations that prevent you from using a lower RTO. Data backups can take significant time to restore, depending on how large they are, where they’re stored, and whether you’re starting a full or partial recovery. There’s no use in setting an RTO of one hour when you know you need two hours to utilize your backups. Analyze your backup regime, test how quickly you can access critical data, and check your RTO is compatible with your findings.
Disaster recovery and RTOs
RTOs are vital during disasters because they provide an unambiguous notification when events begin to unacceptably impact your business. Without an RTO, it can be unclear whether your disaster recovery strategy is effective. An RTO gives you something tangible to measure against, informing whether you can act fast enough when services go down.
Successfully responding within the RTO relies on a cohesive disaster recovery plan for getting services back online. Good strategies are formed from multiple elements that your whole team is familiar with:
- Maintain offsite copies of data. Data needs to be backed up to a location that’s independent of your primary systems. Otherwise, you might find you cannot access your backups when you need them.
- Implement effective incident monitoring. Good observability for your apps and infrastructure is essential so you’re alerted when an incident begins. Missing the start of an incident because you’re dependent on manual monitoring will eat into your RTO before you become aware of the problem.
- Plan for disasters. Plan for disasters and rehearse how you’ll perform. This reduces uncertainty and stress during the recovery procedure. Everyone should understand their role and the steps involved in the strategy.
Once you’ve established your recovery process, you can define your RTOs and look for ways to improve them.
How to improve your RTOs
Very low RTOs in the region of a few seconds or minutes are usually unrealistic for large-scale services with significant volumes of data. You have to recognize the time that will be required to recover that data during an incident.
Nonetheless, there are methods that can improve your RTOs while keeping them attainable.
- Increase backup frequency. Increasing the frequency of your backups improves your recovery point objective (RPO) and can also help your RTOs. More frequent backups can be smaller in size when you’re using an incremental backup technology. They’ll also be quicker to apply over any existing data.
- Use incremental backups. Incremental backups only snapshot the changes since the last backup, instead of creating a fresh dump of all your data. They usually have much smaller sizes so they’re more portable, easier to work with, and quicker to restore. However, an incremental backup might not be usable if you suffer a catastrophe and lose all your data. It’s still a good idea to keep full backups on standby too.
- Locate recovery media close to failover servers. Backups and recovery media should be physically located near your failover servers. This will reduce the time spent transferring data onto your failover nodes, which will help preserve your RTO. Having to move large amounts of data between cloud providers and geographic regions is often slow and expensive.
- Implement synchronous mirroring. Synchronous mirroring is a backup strategy that automatically copies data to a remote secondary site as it’s written to the local primary storage. It guarantees there’s a continually written replica of your datastore, eliminating the risk of data loss because a scheduled backup hasn’t run since the last write. Synchronous mirroring can improve RTOs by letting you assert the backup is current, reducing the time spent identifying a backup to recover.
- Choose backup tools with granular recovery. Granular recovery options allow you to selectively recover parts of your data. This could be one table from a database or a single file that a user has deleted. The granularity substantially accelerates recovery when an incident’s caused by damage to a specific asset. You only need to retrieve the affected data from storage, a task that’ll be much quicker than running a full backup restoration.
- Set up automatic failovers. Allowing your systems to automatically failover to a secondary site can avoid your RTOs being consumed when the primary suffers a problem. Use continuous replication technologies such as synchronous mirroring to clone your data across both sites. Deploy your applications into each environment, then configure your infrastructure to direct requests to the secondary if the primary becomes unhealthy.
These techniques will accelerate your disaster response, allowing you to set lower RTOs.
Conclusion
Recovery time objectives define how much downtime you can tolerate before an incident must be resolved. Exceeding the RTO means that your business operations have been interrupted. This will be noticed by customers and could have negative repercussions for your organization, whether financial, regulatory, or reputational.
Setting a low RTO doesn’t guarantee you’ll achieve it unless it’s part of a comprehensive disaster recovery plan that’s carefully supported by tools and procedures. Try using Rewind’s data protection platform to backup your applications and accelerate their restoration. Rewind gives you immediate access to your critical data and lets you restore it in just a few clicks. This efficiency can help you reduce your RTOs and make bigger promises to customers.



