The importance of having a backup for your database has been a hot topic in recent years. Yes, the data your application presents to users is kept in the database, but what about how you show people that data? A database doesn’t do you much good by itself—you also need the code or program that renders your web application.
Even though it’s just as business-critical as your databases, backing up your code remains a less common concern. It shouldn’t be, though, and in this article, you’ll learn how to use a simple backup script to help you back up code that’s stored on GitHub.
Why back up GitHub data?
When starting a new project, you usually start with your local machine. In most cases, when you’re done, you upload the code to an online repository to store your code and help smooth the process of taking your code to production or collaborating with other programmers. The most prominent online repository platform is GitHub.
Although GitHub is fairly secure, not to mention backed by the tech giant Microsoft, it does have downtime, which can be costly for some businesses. There’s also a possibility that code stored on GitHub could be deleted by user error or by an administrator in an organization’s repository.
While deleted GitHub repositories can be restored, the code in question must not have any forks, and recovery must be done within ninety days of deletion. It can also be a fiddly, time-consuming process. Without a backup, you could lose a lot of time like this—or worse, lose a major piece of software.
Writing a GitHub backup script
Several open source packages contain a script to help back up your code from GitHub, so you don’t have to start entirely from scratch.
The most popular and feature-rich is the python-github-backup by Jose Diaz-Gonzalez] Using this package, you don’t just back up your repository but also issues and wikis.
However, for this article, we’ll be taking a look at a more nimble backup script by abusesa and making some slight modifications. This package is open source under the MIT License and allows you to back up a GitHub repo with ease.
If you’d like to follow along, the complete script is available in this repository.
What your backup script needs
Before you can start, you have to specify what you want to back up and where you want the backed-up files to be saved. Inside your terminal, create a new folder called `github-backup-script` using the below command:
$ mkdir github-backup-script
Move inside the folder:
$ cd github-backup-script
Create two files, one for the script and the other for the config variables:
$ touch backup.py config.json
Open the file `backup.py` in a text editor. Copy and paste the code, which contains several functions, into the file.
However, replace the `check_name` function with the following code:
def check_name(name):
if not re.match(r"^\w|-|\.[-\.\w]*$", name):
raise RuntimeError("invalid name '{0}'".format(name))
return name
This resolves an issue that was opened on this package.
Now, you’ll go through what each function in the `backup.py` file does and run a quick example.
This backup script was written in Python, and to work with it, you’ll need to have Python 3.6 or later installed. If you have a little knowledge of the Python programming language, it will make it easier to follow along with this post and understand the code.
You’ll also need to install a third-party package called `requests` by running the below command in your terminal:
$ pip install requests
Some users may find that due to how Python was installed on their computer, running `pip` returns a “command not found” error. Look at these workarounds to resolve the issue.
Inside the `backup.py` file, we have four functions and the main function. The main function is what runs and can call other functions when needed.
The first function is called `get_json()` and will return a JSON object of the result we get from the GitHub API.
The second function is called `check_name()` and checks if the repository name is valid.
The third function is `mkdir()`, which makes a new directory of the repository on your local system.
The fourth is called `mirror()`, and fetches the code from your GitHub remote repository to your local system as bare repositories.
Running the backup script
Inside the `config.json` file, add the following code:
{
"token": "",
"directory": "~/backups/github.com",
"owners": ["Samuel-2626"]
}
You’ll need to generate a personal access token to authenticate you as a valid GitHub user. Before generating the token, you’ll be asked to select the scope of it. Select the repo checkbox only, then generate the token.
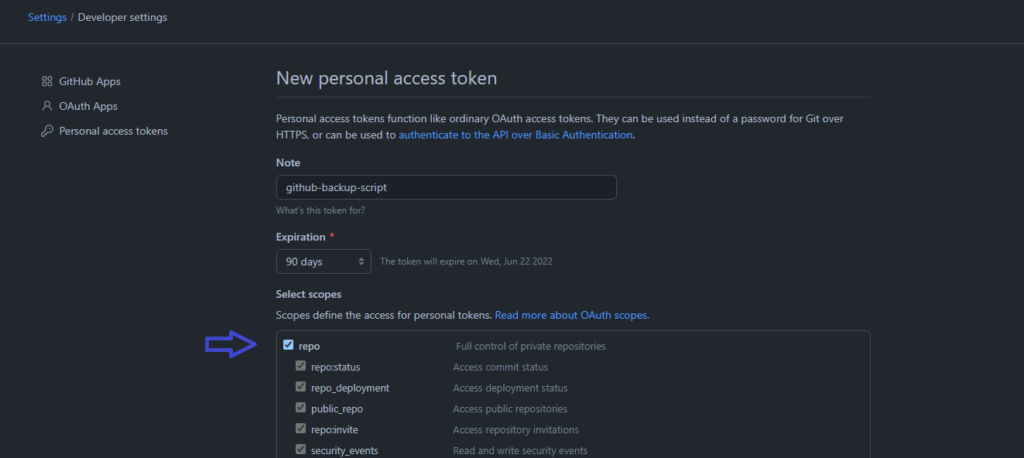
Once you’ve generated a new token, paste it into `config.json` as the token value.
The directory value specifies the folder to which the backups should be saved. The owner’s value is optional, but specifying it indicates that you want only the repository that is inside your account to be backed up, and repositories associated with organizations you belong to should be excluded.
To run the script, use the below command:
$ python backup.py config.json
It receives an argument, which is the config file. This will successfully back up all the repositories from your GitHub account.
When you run the script, you’re downloading to your local repository all of the remote repository’s refs and objects, as well as any new branches. The output you get is what’s usually found in the `.git` folder of the original repository. This `.git` folder contains almost everything that git stores and manipulates. To get a working directory for a particular repository, run the command below:
$ git clone <the-github-repo-name> <the-working-directory-name>
Replace `the-github-repo-name` with the repository name and `the-working-directory-name` with the directory you want the code to be cloned to. This will extract all the files and folders to the working directory.
Limitations and alternatives
Writing your backup script or leveraging an open source package and modifying it like what we did earlier has some limitations.
Those solutions come with a lot of overhead, as you have to go through the code and see if it is the right solution for you. This is another limitation in itself since you’ll be limited to programming languages you’re familiar with. Additionally, most of the solutions are not particularly feature-rich and may have limited ability to restore metadata, like issues and pull requests.
This option has other complicating factors as well. Backing up with a script, you have to manage where the backup data is stored, both in terms of having the storage available and in ensuring its security. Then, on top of everything else, you have to keep an eye out for any API changes that might affect your ability to connect to GitHub and manage the codebase.
Using a backup script might be a good option for a very small team or a casual one-person project. However, as your project grows, it’s worth considering a SaaS company like Rewind that offers you the ability to back up your data with no overhead maintenance, lots of helpful features, and a user-friendly interface. You can automate your backups, and if you need to restore, it only takes one click—no wasting time fussing with scripts. Plus, Rewind Backups for GitHub can backup and restore all metadata associated with your repo, including commits, comments, issues, and more essential info.
Conclusion
Just like a database can be corrupted, your codebase can also be corrupted. In this article, you’ve learned about the importance of backing up your code. You’ve also looked at an open source backup script, including the purpose of the functions, and made a slight modification.
You’ve also learned about Rewind, the only SOC 2 Type 2 compliant app verified by GitHub. It provides a one-click, set-it-and-forget-it alternative to tedious and error-prone manual backups. It automatically keeps your backups up to date, allowing your devs to focus on creating value for your customers. You’ve already backed up your database; protect your business by backing up all of your other data, too.
 Sarah Bader">
Sarah Bader">