
We process quite a large amount of webhooks from online SAAS applications at Rewind. Webhooks are triggered for us by the web apps we backup whenever something changes (ie. in a Shopify store, if an item changes we receive a webhook for the item). When we receive the webhook, we take some action to back up whatever the webhook refers to. Last month, we received and processed over 200 million webhook requests, so having a solution that scales to meet this volume is critical.
In a previous blog post, Rewind CEO Mike Potter wrote about how to handle Shopify webhooks at scale and if you’re attending Shopify Unite this year, I’ll also be giving a lightning talk on June 20th with a little more about how we do this. (update: you can watch that talk on YouTube now) This post outlines how we recently added some basic caching in AWS to significantly reduce the load on our downstream services and provide even more webhook throughput.
Refresher
Before delving into the change, here’s a quick refresher on our webhook process today:
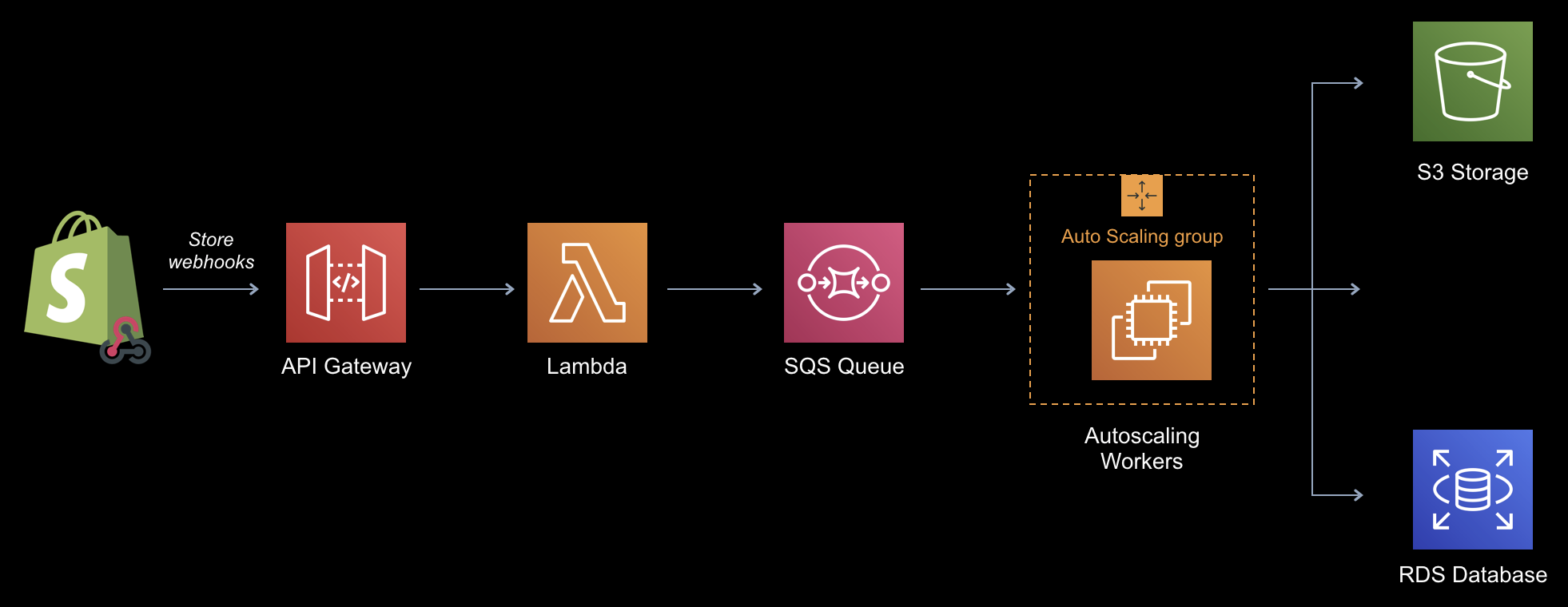
In the diagram above, webhooks that come from the platforms, in this example Shopify, are received by AWS API Gateway (which exposes our webhook endpoint) and passed onto our Lambda function. This function calls one of our internal API endpoints to determine which SQS queue to route the webhook to. Once it’s routed to the queue, a set of worker processes pick them off, back up the item and write them into a couple of data stores (S3 and RDS in this case). This all works incredibly well and the use of the Lambda function gives us virtually limitless scalability.
Webhook bottleneck
Generally, this solution just works. The Lambda is simple enough and executes fast enough that we never miss processing a webhook because the reception and the process is nicely decoupled. Most webhooks demand a response in under 5 seconds and with the Lambda only doing a simple lookup and placing the item on a queue, this time constraint is very easy to meet.
But what happens when we get a sudden influx of webhooks like this case:
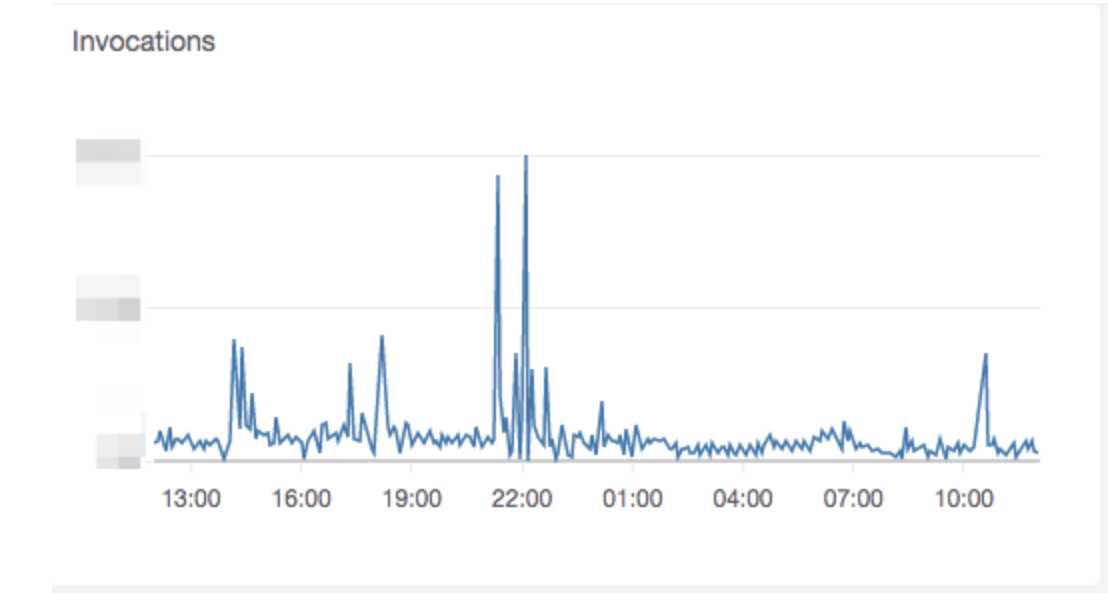
This graph shows the number of invocations of one of the Lambda functions processing webhooks from a single platform. You can see we went from a fairly steady state of invocations to a big spike around 22:00. Usually, in this case, we find that a single customer has made a bulk change to their e-commerce store (imported a large number of items for example).
What happens, in this case, is AWS Lambda increases its number of concurrent invocations to handle the new load coming from API gateway up to a maximum number of concurrent executions set by AWS. This is, in turn, means we have more concurrent requests hitting our internal API endpoint looking up which queue to route the webhook to. Because the API is backed by a Postgres RDS database, we have found that we were running out of database connections occasionally when these bursts occurred. We could have limited the concurrency of the Lambda function or increased the size of the database but both options were not palatable – we want more scale for less resources!
Was there something else we could do? There is!
How we got more scale for less resources
We had talked about some kind of caching solution to this problem every now and again around the office. Solutions involving Redis or even a simple DynamoDB table that only contained the queue routing. Both options seemed doable but I was wondering if there was something simpler that would cover the 90% case.
AWS Lambda executors and their environment (where your function is running) stay “alive” for a certain duration. This means your function can execute very quickly for subsequent executions (imagine a longer running Docker container). Because the executor lives for some time ( this post shows some data about how long they live), you can actually cache some data inside the environment. I’d taken advantage of this in a previous solution which, dynamically loads AWS Athena partitions by writing some temporary data to /tmp inside the execution environment.
Could we use the same strategy here?
The answer was YES and the eventual solution also shows how peer review of pull requests is an incredibly powerful process. I modified the Lambda function which processes the webhook to cache the response data from our API and write the resulting JSON blob to a file in /tmp in the Lambda execution environment. This worked well in testing and I duly submitted a pull request for peer review. This review was fantastic in two ways:
- Our Lambdas are written using NodeJS – Javascript is not my first language so being able to review this with those in the team who are “JS whizes” was very helpful.
- One of the chaps suggested, what seems obvious now, why not cache the response in memory?
Of course! While Lambda functions do have a memory limit (which you can select when defining the function), our current executions are well below the minimum 128MB threshold. I think we are using around 32MB but we’re still paying for the minimum which is 128MB.
It turns out that any global variables defined outside the function handler persist for the life of the environment. Perfect! I was able to come up with this (abridged) change. The relevant parts to the change are in bold:
'use strict';
let podDetailsCache = {}; // Defined outside the function globally
RewindApiClient.prototype.getPodDetails = function(platformId, callback) {
if (platformId in podDetailsCache)
{
console.log(`Cache hit for ${platformId}`);
this.data = podDetailsCache[platformId];
return callback(this);
} else {
console.log(`Cache miss for ${platformId}`);
const request = https.request(params, (response) => {
let statusCode = response.statusCode;
if (statusCode != 200) {
this.error = new Error('Request Failed.\n' + `Status Code: ${statusCode}`);
return callback(this);
}
let rawData = '';
response.on('data', (chunk) => { rawData += chunk });
response.on('end', () => {
try {
this.data = JSON.parse(rawData)[0];
console.log(`Writing to cache for ${platformId}`);
podDetailsCache[platformId] = this.data;
return callback(this);
} catch (error) {
console.log(`Error parsing the response: ${error.message}`);
this.error = error;
return callback(this);
}
});
})
request.on('error', (error) => {
console.log(`RewindApiClient encountered an error while executing getPodDetails: ${error.message}`);
this.error = error;
return callback(this);
});
request.end();
}
};
Essentially, by defining a global object and then writing to or reading from it, we have a simple form of cache with no external infrastructure needed. Because the amount of memory needed for the API response is very small and because the Lambda environments are cycled, I’ve found that we never use more than 40MB of memory, which is still well below the 128MB limit I’ve set for the function.
We get a lot of cache misses due to the Lambda environments cycling out but we are saving millions of calls to our API endpoint.
Results
Sometimes, the simple solutions are the best solutions. I’ve been keeping an eye on this since we put it into production and here’s a small graph showing the number of cache hits from our logging tool Papertrail:
The spike in cache hits at around 18:00 EST directly coincides with the Lambda executions graph in the first part of this post. More activity equals more cache hits. This is exactly what we wanted to achieve with this solution.
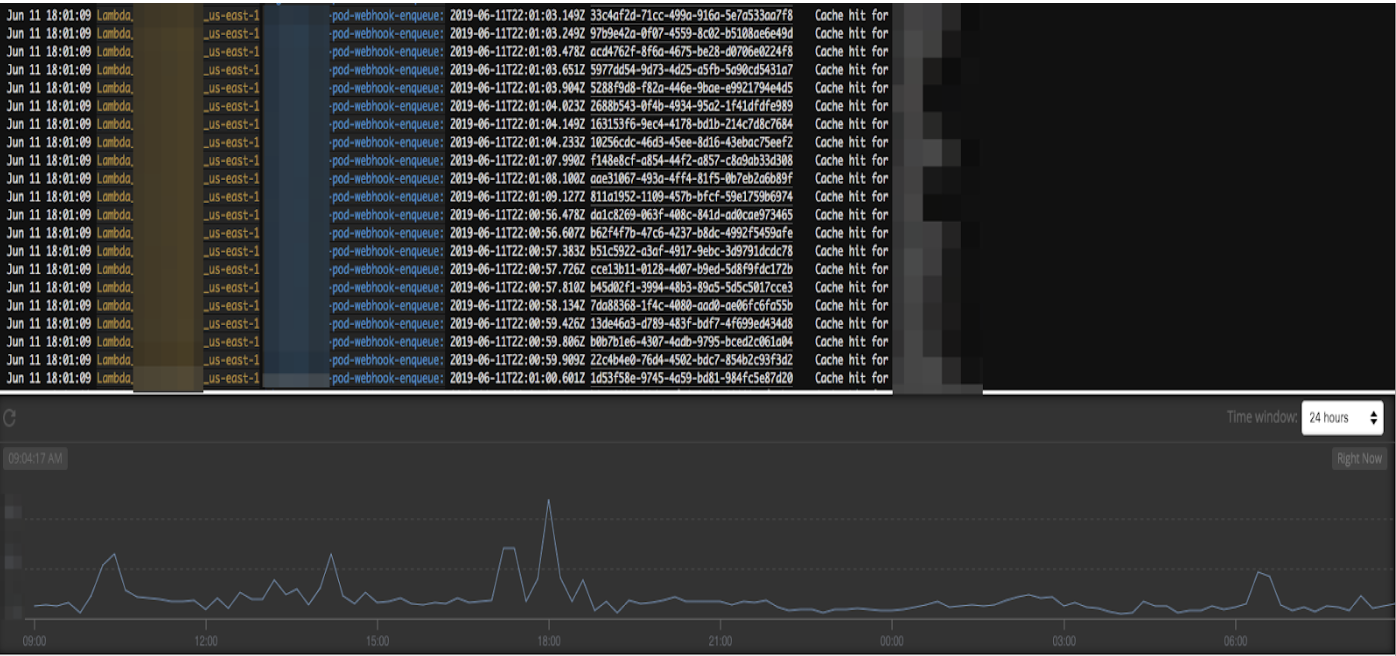
Further, when I check the load (both on the endpoint itself and the database in the back end) on our internal API at this time point, there’s no appreciable difference in the normal state. Great success!
I am confident that we have covered off the 90% case where we had a minor scaling problem with the current solution.
Could we have designed a more full-featured caching solution?
Yes. But sometimes the simple solutions are more than good enough. In this case, four lines of code and knowing how the AWS Lambda environments persist was enough to solve the problem.
For more information about Rewind, please head on over to rewind.com. Or, learn more about how to backup Shopify, backup BigCommerce, or backup QuickBooks Online.
We’re hiring. Come work with us!
We’re always looking for passionate and talented engineers to join our growing team.
View open career opportunities Dave North">
Dave North">


