
Pop quiz: you log into work one morning, and all your data is gone. Your systems are down. What do you do, hotshot? What do you do??
It’s a classic action movie moment, but it’s also an excellent teachable moment for CloudOps professionals. A disaster recovery plan is essentially the answer to that question: the worst has happened (there may or may not be a bomb on the bus). What do you do now?
Rewind’s CloudOps and Security teams recently updated our disaster recovery process with a new planning exercise. Here’s what we learned.
Understanding RTO and RPO
Two basic metrics are important in DR plans; Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
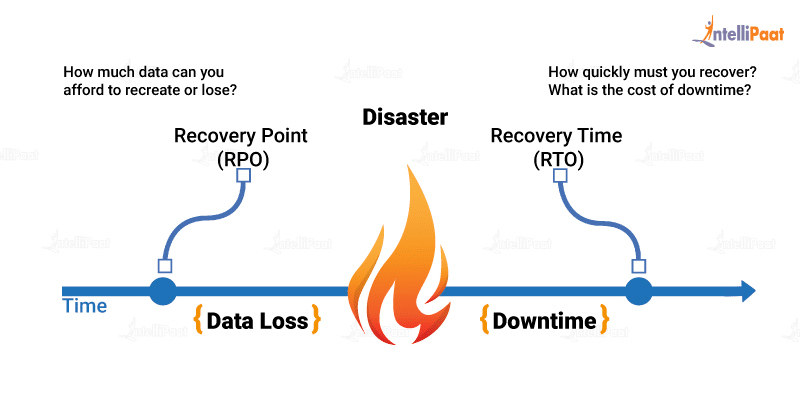
Recovery Point Objective, or RPO, is basically, “How much data can you afford to lose?” For example, if we’re taking backups once a day at midnight and a disaster happened at 11:59 pm, we would lose one day’s worth of data. That may or may not be acceptable to you. The definition of acceptable RPO numbers will vary, depending on the organization.
Defining your risk tolerance for data loss determines how you answer the question, “What are you going to do technically to meet these requirements?”
The other metric is Recovery Time Objective (RTO). If a meteorite hits our data center, how long would it take us to recover? Let’s say we have to bring in another Rewind from somewhere else. How long does that take? Some services could recover in maybe five minutes. Other services might take a whole day.
So your RPO and RTO will vary depending on what services you want to protect with a Disaster Recovery plan. So, start there. Identify your RPOs and RTOs, get buy-in from your stakeholders, and then everything will trickle down from here.
Recovery strategies: balancing robustness with cost
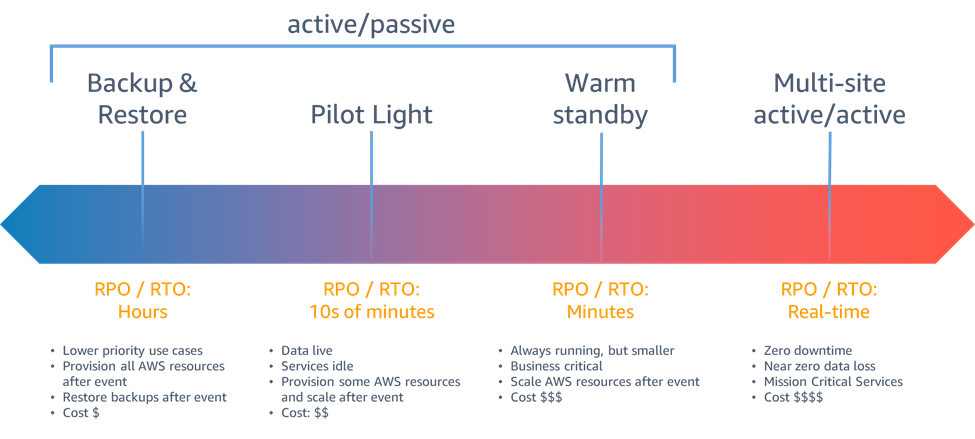
As far as recovery strategies go, there’s a sliding scale of robustness linked to cost. As you go further to the right, the RPOs and RTOs decrease, but the cost increases.
- The Backup & Restore solution on the left is relatively simple. This is the easiest and cheapest option; recovery time is measured in hours and maybe longer. Essentially you are restoring your last backup(s) to the DR location.
- The Pilot Light option means that you run some of the services that you would need but in a reduced capacity. Generally, most services are running but in a “scale to zero” capacity. Code or application updates are pushed to the DR location in the same way you would update your primary location.
- On Standby, everything’s running, but at a smaller capacity. This is similar to the Pilot Light option, but you’re running all services and with at least some capacity (i.e., nothing is scaled to zero)
- The last one is a true Active/Active solution. You’re essentially running full services in two parallel streams, and you can switch between them in near real time. But effectively, your costs here are doubled. For many companies, this is cost-prohibitive.
Your recovery strategy depends on your risk tolerance, which of course, varies. How much you want to spend to abate that risk becomes a business decision.
Almost every organization will have multiple services that make up their business. Depending on what business you’re in, you’ll likely have core systems that constitute the foundation of your operations, as well as more peripheral systems. A core system being down a full day would be painful for many businesses, but if tools for running marketing programs and, let’s say, gathering statistics were offline for a day, it could have much less of an impact.
Different services have different requirements for how quickly they need to be available, which means that you really have different DR plans for different systems within your organization. Often there is a great deal of overlap between service DR plans but it’s important to consider each service’s plan due to the potentially varying RPO/RTO.
Cloud hierarchies and your DR plan
Most cloud services, whether it’s Amazon, Azure, Google, or any of the other numerous cloud providers, share a similar hierarchy. In Amazon’s case, the AWS service is split into different Regions, and each Region includes several Availability Zones or AZs. For instance, the Region AWS US East in Northern Virginia has 6 AZs.
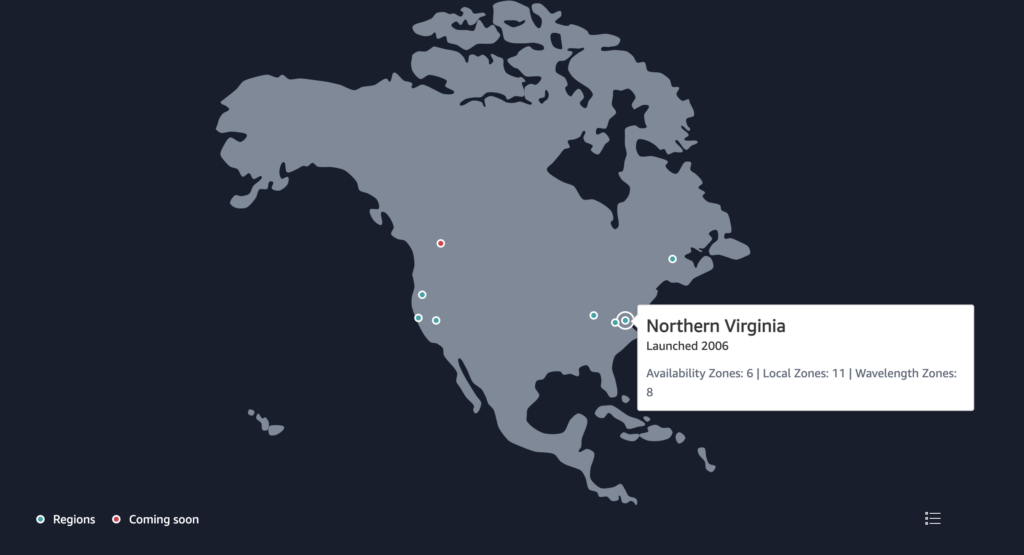
You can think of an Availability Zone as being like a physical data center. While in many cases, there are many physical sites that make up a single AZ, thinking of an AZ like a physical data center is a reasonable simplification when considering DR planning. Each of the red AZ dots on this map is a building with a bunch of servers, racks of gear, air conditioners, and all this kind of stuff. Each AZ is pretty reliable, but stuff does happen that can take them offline. We’ve seen a few cases where construction crews accidentally cut off fiber cables, and there was a fire once that took out a single AZ in Germany.
It’s a cloud best practice to architect all your services to run across at least two Availability Zones. Most companies are made up of many services that are glued together. It’s important to run every single one of those services redundantly across at least two AZs, just in case one fails.
Let’s say we were running our services across two red dots on the AWS map, and there was a fiber cut affecting an entire AZ. All network communication with that AZ is suddenly gone. Our services would continue to work automatically in the second red dot, requiring no human interaction at all. Services have to be architected to run across multiple AZs, but the effort is well worth it.
At Rewind, we run our services across a minimum of two AZs, but for the AWS Simple Storage Service (S3), AWS automatically, behind the scenes, replicates the data in S3 across three availability zones. You’d have to lose three AZs simultaneously or have the entire region hit by a meteor for things to go south.
In essence, the risk of losing data in S3 is very small. The concept of “Five Nines,” or 99.999% uptime, equals a maximum of 5 min of total downtime in a year. S3 is designed to provide 99.9999999999% durability (losing data forever) and 99.99% availability (being able to access that data). This means that if you store your data in S3, the risk of losing data permanently is 1 in 100 billion.
If you architect your system to work across multiple available sites, you get regional disaster recovery with AWS for free.
During our DR planning, we reviewed each of our services and ensured that everything was configured and capable of running across at least two Availability Zones. Our audit found that 85% of our services were already designed and operating across multiple AZs, but we found a few peripheral ones that didn’t, which we addressed. Going through a thorough review of our DR process allowed us to catch a few things we might not have noticed otherwise.
Issues with individual AZs are relatively straightforward. In most cases, we don’t have to intervene – AWS magic happens and we just monitor. We can shift things around a bit if we feel we need more capacity for specific services in the short term, but the shift from the damaged AZ to the remaining AZ happens automatically.
The more challenging piece is to determine what to do if an entire Region is devastated by a meteor or earthquake.
A Region is a collection of Availability Zones. It’s rare that a cloud provider has an event that affects an entire region, but it has happened. Usually, a key managed service has an issue in a region that affects many other services and effectively makes the entire region unusable. There can also be catastrophic events —a meteor striking the US east coast, widespread flooding, or The Big Earthquake hitting California could take out an entire Region. These are highly unlikely compared to, say, a fiber cut taking out a single AZ – but they are possible, and no DR plan should be considered complete without accounting for the loss of a full region. Responding to the loss of a full region is a lot more complicated because things like data availability and service redundancy then fall to us.
All this feeds into the risk profile and how much you are willing to spend to make things available. When you’re talking about Disaster Recovery, you have to consider questions like “what is the likelihood of this scenario happening?” and “how much am I willing to spend to mitigate this risk?”
The “human side” of DR: the importance of tabletop testing
There are two main pieces to Disaster Recovery plans: the technical aspect, including the literal commands you need to run to restore service, and the more human side (more on that in a bit).
I have an engineering background, so I was initially focused on the technical side. What do we need to do if a disaster happens? Say a meteor hits North Virginia, where we host most of our services; what would we need to do? What actual commands would we run? How would we replicate data and configuration?
The team at Rewind went through and documented our entire technical procedures, including commands to run, configurations to update, and Infrastructure-as-code to apply in case of a full region disaster. Do that, run this, stand on one leg, and hold up an umbrella.
You need to test that plan to make sure it’ll work. So, we tested all of these commands in a test environment. You can (and should) do some level of live DR testing in production, but as a first cut, testing in a good test/staging environment that mirrors production is a great starting point. That took a long time, but we got that done as part of our DR strategy.
At this point, our compliance wiz, Megan Dean, who has prior experience running DR testing, ran us through what’s called “tabletop testing.” Essentially, as the name sounds, we all sit around a table (or virtual table!) and work through a DR scenario and say, what would we do if “X” happened?
The tabletop test is similar to a group of people playing a board game, like Dungeons and Dragons. Everyone around the table has a persona, a character, and they each play a different role in disaster recovery.
Megan laid out the scenario: we’d just received a notification that there was a fire in the AWS Virginia region, impacting multiple availability zones. Oh, and it’s the day before Black Friday (one of Rewind’s highest-traffic days of the year). What do we do?? We had to respond to the scenario as if it was real.
The tabletop test was actually the most exciting element to me, A) because I’ve never done it, and B) because it revealed another side to DR planning I hadn’t spent enough time contemplating: the non-technical process of DR failover. This part looks into questions like:
- Who has the authority to say we’re going to do a DR failover?
- Who from the leadership team needs to be notified?
- Who from customer support needs to be involved?
- Do we need to notify anybody from a privacy perspective or regulatory perspective?
The tabletop test helps figure out all this other stuff that, honestly, I just hadn’t put enough thought into. The exercise was extremely valuable because the technical runbook for a disaster recovery scenario is only half of the solution. Simply knowing what commands to run isn’t helpful if you don’t know who can run those commands and under what circumstances. You need those technical commands in a DR runbook, but you also need to flesh out the plans, processes, and procedures around that runbook. It’s the combination of both pieces that really make up the full DR plan.
We spent most of the day in our tabletop test not going over our technical steps to recovery, but the procedures around them. The non-technical runbook outlines what to do in every type of disaster we could conceive of. There’s an invocation procedure, which outlines what exactly is considered a “five-alarm, holy crap, drop everything fire” and what isn’t. We cover both types of disaster – losing an AZ or a full region. We’ve got a notification tree to ensure everyone is alerted to the situation as soon as possible. It’s like a flowchart of steps to take for specific disasters. What to do, who needs to be notified, who needs to be contacted, everything.
For each of the services that make up Rewind and the type of disaster (AZ or region), we’ve documented:
- What’s our RPO and RTO?
- How do we know we have a failure?
- What are the actions required?
The reason we did this tabletop test (and will regularly do it again in the future) is that the best time to create a fire response plan is when your house isn’t on fire. It’s always better to ID potential problems in a simulated, representative scenario, not during the real thing when stakes are high and stress levels are higher.
This way, we avoid “chickens running around with their heads cut off” type scenarios with a clear plan. If we do happen to be driving a bus, and it’s got a bomb that’ll go off if we slow down below 50, we’ll know what we’re gonna do, hotshot.
 Dave North">
Dave North">


